微信红包的随机算法是怎样实现的?
155 个回答

有人问过微信的人,大致是这样:
先上代码:
public static double getRandomMoney(RedPackage _redPackage) {
// remainSize 剩余的红包数量
// remainMoney 剩余的钱
if (_redPackage.remainSize == 1) {
_redPackage.remainSize--;
return (double) Math.round(_redPackage.remainMoney * 100) / 100;
}
Random r = new Random();
double min = 0.01; //
double max = _redPackage.remainMoney / _redPackage.remainSize * 2;
double money = r.nextDouble() * max;
money = money <= min ? 0.01: money;
money = Math.floor(money * 100) / 100;
_redPackage.remainSize--;
_redPackage.remainMoney -= money;
return money;
}
以上代码仅供参考,涉及商业计算要用java.math.BigDecimal. 感谢 @xin lu、 @秦时明月 指出。
再说结论:
- 先抢后抢拿到红包的大小的期望是大致相等的,所以还是先下手抢吧
- 后抢的人方差大(依赖前面人抢的多少),波动较大,有较大几率拿到“手气最佳”
祝大家抢红包快乐哦~
测试数据。
测试结果测试随机红包
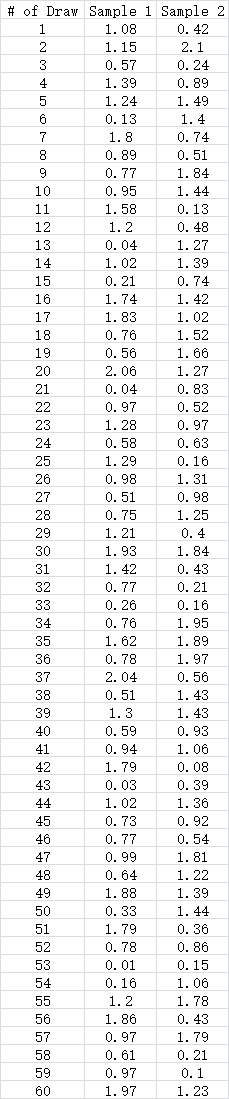
以上面的初始化数据(30人抢500块),执行了两次,结果如下:
// 第一次
15.69 21.18 24.11 30.85 0.74 20.85 2.96 13.43 11.12 24.87 1.86 19.62 5.97 29.33 3.05 26.94 18.69 34.47 9.4 29.83 5.17 24.67 17.09 29.96 6.77 5.79 0.34 23.89 40.44 0.92
// 第二次
10.44 18.01 17.01 21.07 11.87 4.78 30.14 32.05 16.68 20.34 12.94 27.98 9.31 17.97 12.93 28.75 12.1 12.77 7.54 10.87 4.16 25.36 26.89 5.73 11.59 23.91 17.77 15.85 23.42 9.77
对应图表如下:
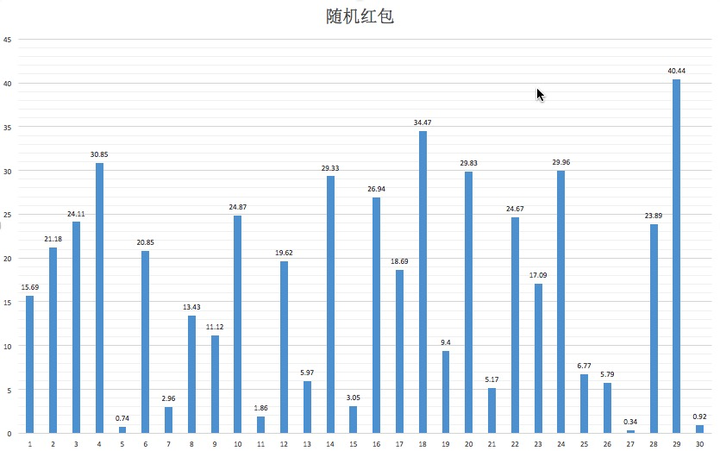

还有一张:
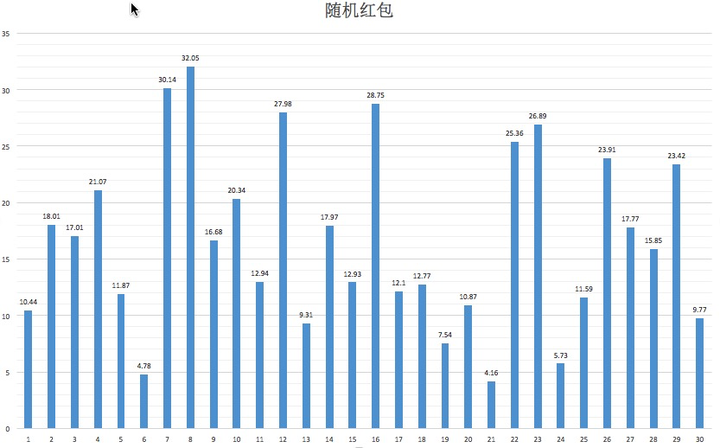

多次均值
200次
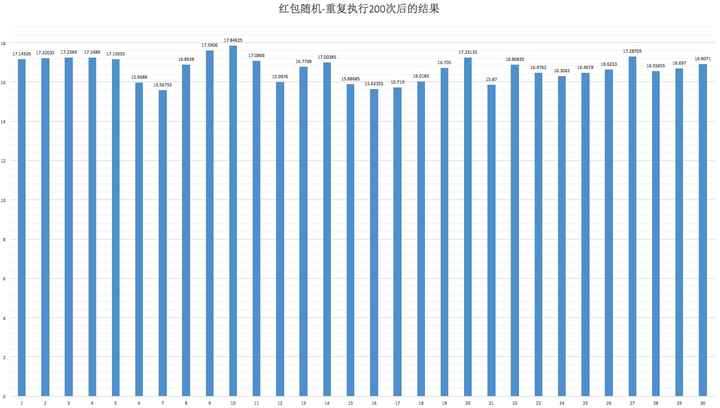

2000次
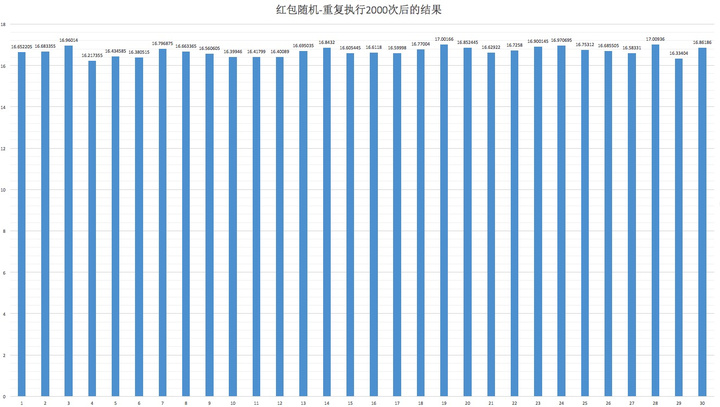

可以看到,这个算法可以让大家抢到的红包面额在概率上是大致均匀的。
转一下原文
微信红包的架构设计简介
@来源于QCon某高可用架构群整理,整理朱玉华。
背景:有某个朋友在朋友圈咨询微信红包的架构,于是乎有了下面的文字(有误请提出,谢谢)
概况:2014年微信红包使用数据库硬抗整个流量,2015年使用cache抗流量。
1. 微信的金额什么时候算?
答:微信金额是拆的时候实时算出来,不是预先分配的,采用的是纯内存计算,不需要预算空间存储。
采取实时计算金额的考虑:预算需要占存储,实时效率很高,预算才效率低。
2. 实时性:为什么明明抢到红包,点开后发现没有?
答:2014年的红包一点开就知道金额,分两次操作,先抢到金额,然后再转账。
2015年的红包的拆和抢是分离的,需要点两次,因此会出现抢到红包了,但点开后告知红包已经被领完的状况。进入到第一个页面不代表抢到,只表示当时红包还有。
3. 分配:红包里的金额怎么算?为什么出现各个红包金额相差很大?
答:随机,额度在0.01和(剩余平均值*2)之间。
例如:发100块钱,总共10个红包,那么平均值是10块钱一个,那么发出来的红包的额度在0.01元~20元之间波动。
当前面3个红包总共被领了40块钱时,剩下60块钱,总共7个红包,那么这7个红包的额度在:0.01~(60/7*2)=17.14之间。
注意:这里的算法是每被抢一个后,剩下的会再次执行上面的这样的算法(Tim老师也觉得上述算法太复杂,不知基于什么样的考虑)。
这样算下去,会超过最开始的全部金额,因此到了最后面如果不够这么算,那么会采取如下算法:保证剩余用户能拿到最低1分钱即可。
如果前面的人手气不好,那么后面的余额越多,红包额度也就越多,因此实际概率一样的。
4. 红包的设计
答:微信从财付通拉取金额数据过来,生成个数/红包类型/金额放到redis集群里,app端将红包ID的请求放入请求队列中,如果发现超过红包的个数,直接返回。根据红包的逻辑处理成功得到令牌请求,则由财付通进行一致性调用,通过像比特币一样,两边保存交易记录,交易后交给第三方服务审计,如果交易过程中出现不一致就强制回归。
5. 发性处理:红包如何计算被抢完?
答:cache会抵抗无效请求,将无效的请求过滤掉,实际进入到后台的量不大。cache记录红包个数,原子操作进行个数递减,到0表示被抢光。财付通按照20万笔每秒入账准备,但实际还不到8万每秒。
6. 通如何保持8w每秒的写入?
答:多主sharding,水平扩展机器。
7. 据容量多少?
答:一个红包只占一条记录,有效期只有几天,因此不需要太多空间。
8. 询红包分配,压力大不?
答:抢到红包的人数和红包都在一条cache记录上,没有太大的查询压力。
9. 一个红包一个队列?
答:没有队列,一个红包一条数据,数据上有一个计数器字段。
10.有没有从数据上证明每个红包的概率是不是均等?
答:不是绝对均等,就是一个简单的拍脑袋算法。
11.拍脑袋算法,会不会出现两个最佳?
答:会出现金额一样的,但是手气最佳只有一个,先抢到的那个最佳。
12. 每领一个红包就更新数据么?
答:每抢到一个红包,就cas更新剩余金额和红包个数。
13.红包如何入库入账?
数据库会累加已经领取的个数与金额,插入一条领取记录。入账则是后台异步操作。
14. 入帐出错怎么办?比如红包个数没了,但余额还有?
答:最后会有一个take all操作。另外还有一个对账来保障。
原文链接:微信红包的架构设计简介
---
关于金钱,其他回答推荐:

今年过年我花了120元做了一组实验(其中60元由老婆的红包赞助,特此鸣谢 ^-^ ),获取了两个样本。两个样本的大小均为60人。经过对样本的分析,我的结论是:我赞同土豆的第一条结论,也就是获取的钱数有可能符合截尾正态分布;但不赞同土豆的第二条结论 -- 我的两个样本结果显示,后抽取的人未必获得更多的钱。很有可能腾讯在一个钱包上传时就已经用算法将红包分成了给定份数,接下来抽取人去抽取钱包的时候只是按照时间顺序把给定份数的钱包给抽取人罢了。补充一点:假设陈鹏先生的算法是正确的(亦即此算法确实是微信红包的算法),那么先抽取者与后抽取者获得红包大小的期望值是相同的,但是标准差不同。根据个人的风险偏好的结构(risk preference structure)不同,风险回避(risk-averse)的抽取者应该尽量先抽,而风险偏爱(risk-seeking)的抽取者应该尽量后抽。 【陈鹏先生的算法是否可信以及整体到底符合何种分布都有待于更多的样本进行检验。目前我没有找到反例】
以下为验证部分。
首先,我来讨论一下为什么要采用截尾正态分布。首先介绍一种更加直接的方法(我有一些朋友也这样猜测):如果我有50元,要发给25人。那么我用连续均匀分布随机产生24个位于0到50之间的数字。这24个数字将整个0-50的区间划分为25份,分别分给这25个人。但事实并不是这样的。学过序列统计的人应该知道,由于这24个点是连续均匀分布产生的,因此他们的序列统计量也是连续均匀分布产生的,因此他们之间的间隔的分布是指数分布的。具体证明从略,可参照John Rice 2007。
若是没有序列统计的背景,我们也可以跑一个模拟。我有60元钱,按照上述数据产生机理随机分成60份(因此人均1元左右),然后如是操作10000次,对数据采取聚集后的归一化处理。由于中心极限定理(Central Limit Theorem),该分布反应整体分布(Population Distribution)。画出柱形图如下:
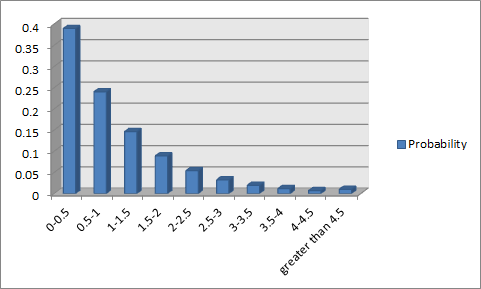

可见是符合指数分布的。
这种产生机理不好的地方在于:大多数人得到的钱非常少,而极少数人得到的钱却非常多,因此可能有一个公平性的问题,而这可能会对抽取人的积极性产生影响。截尾正态分布能够更好地避免这样的问题,因为更多人的红包大小会聚集在平均值附近,而且由于尾部更快的衰减,因此获得特别大的红包的概率也会相应减小,有助于增加公平性与参与的积极性。这一点佐证了土豆的观点,尽管具体截尾的方位可能需要获取更多的数据才有可能有一个准确的预测。
以下是我的两个样本的柱形图:
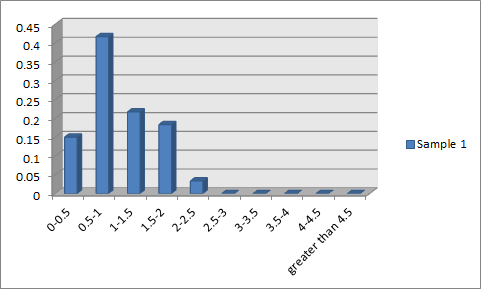

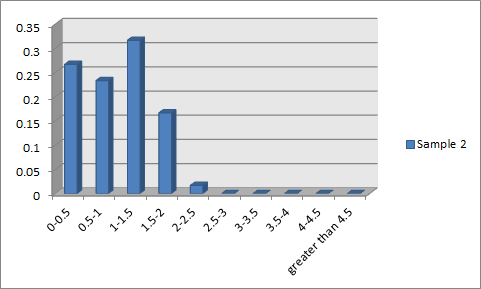

大家可以比照我的柱形图与上面指数分布柱形图。注意到:
1.更多的人获得的红包在均值附近;
2.获取大于2.5元的红包的概率几乎为零(事实上,第一个钱包的最高值是2.06,第二个钱包的最高值是2.10。然而假设是指数分布的(或者说均匀连续分布的数据产生机理),那么在每个60元红包中都会有一定量的抽取者抽到大于3甚至大于4元的红包--这点我通过模拟也确认了。
我进一步对正态假设做了检验,如下为样本1,样本2的分位数图(Q-Q Plot)
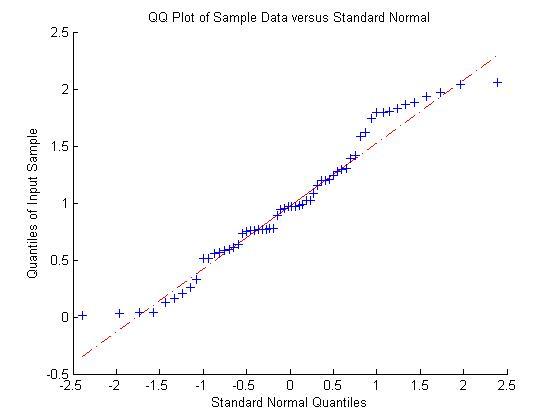

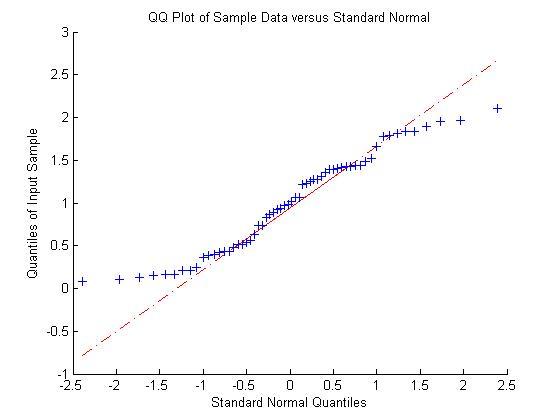

如果完全符合正态分布,那么所有点应该都大致在对角线附近。事实并非完全如此。可见两个样本在一定程度符合正态分布假设,但在两头有一定的异常值。原因有二,一者样本偏小,大数定理不能完全进来,容易有异常值。二者样本是截尾正态分布,所以图和完全正态分布可能有出入。
--------------------------------------------------------------------------------------------------------------------------------
接下去我讨论一下获取钱包大小和抢钱包先后的关系。我的结论是,红包大小和抢红包先后没有统计意义上的关联。
如下是我的两个样本的红包大小数量,我把他们按照时间顺序进行了排序,因此越靠右的人代表越后抢红包的人。
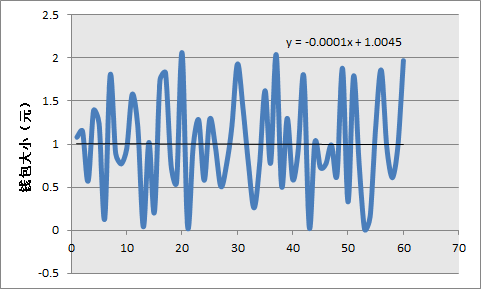

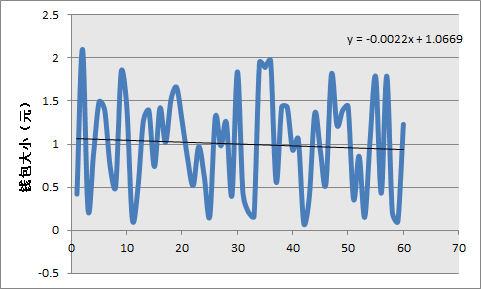

如图可见,其实先抢钱包还是后抢钱包对钱包大小的影响未必有很大的影响。事实上,我的两个样本中,抢到的钱数甚至是随着时间推移逐渐减少的,尽管减少的量非常非常小。因此楼上土豆举的例子中向上走的趋势可能是样本特性,不具有普适性。当然了,我也只有两个样本,更进一步的结论或许有待于更多人搜集并贡献钱包的数据。
事实上,如果我们整合第一个结论,腾讯这样的设计是逻辑自洽的。在第一个结论中,我们谈到了截尾分布相比指数分布的优越性在于其公平性。因此,腾讯选择用截尾分布表明了其对公平性的重视。那么,试想这样一个特意选取产生方式更加复杂的截尾分布增加公平性的企业,为什么要让后抢红包的人获得更大的红包呢?这似乎看起来有些自相矛盾。
综上所述,我的两个主要结论如下:
1)红包大小服从截尾正态分布,其好处是减少抽取红包大小分布的方差,让更多的人抽取的红包在均值附近,同时仍给一小部分人抽取大红包的机会,总体来说增加了红包抽取人的积极性和游戏的公平性;
2)抽取红包大小与抽取红包先后无相关性。一种可能的红包产生机制是:当发红包者<准备红包>的时候,程序自动依照截尾分布产生了相应大小,相应个数的红包,然后随机发给抽取红包的人。同样,这样的一个随机过程有助于增加游戏的公平性,也减少了红包抽取人投机操作(亦即譬如故意等钱包半空的时候再抽取)的动机。我在知乎上看到一位朋友谈到她的腾讯工作的朋友确认了红包产生是在<准备红包>时就完成了的,因此也在一定程度上增强了我的这种推测的可信度。
-------------------------------------------------------------------------------------------------------------------------------
PS: 我看到知友陈鹏先生贴上了微信的算法。我用陈先生的算法研究了一下抢红包的人抢到红包大小和抢红包先后的关系,想与大家分享一下研究结果。
陈鹏先生的代码大致意思是这样的:假设有100元钱,分给十个人。那么第一个人获得红包大小怎么计算呢?100/10 = 10元。这是期望值。从0.01到20的区间中(其中20=10乘以2)随机抽取一个数,就是第一个人获得红包的大小。假设第一个人获得了15元,那么剩下的85元平均分给9个人,这九个人平均获得红包大小为9.4元,那么第二个人的红包大小均匀分布于0.01元到18.80元的区间中,依次类推。算法保证最后一个人至少抽到0.01元。
不难看出,每个人获得的红包大小的期望值仍然是10元。但是分布就不同了,因为之前抽取的人结果的好坏会影响到后抽取的人的结果。假设陈鹏先生贴的算法是可靠的,亦即微信确实用这样的算法来分配红包,我简单模拟了一下第一个抽取的人,第五个抽取的人,以及最后一个抽取的人(第十人)的红包大小的分布如下:
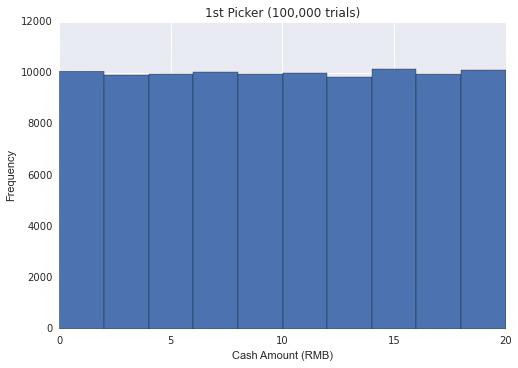

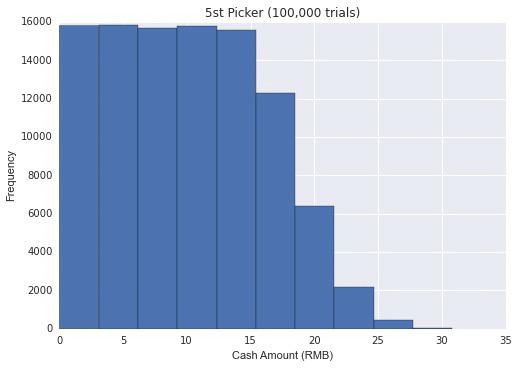

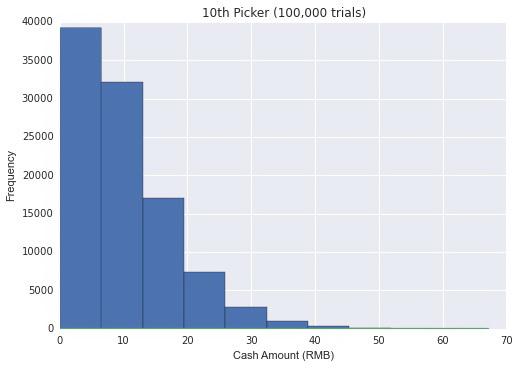

如图显见,对于第一个抽取红包的人,抽取红包大小服从均匀分布,但越到后面的抽取者抽取红包大小的分布就越不均匀。越到后面的抽取者越有可能抽到小的红包,但也有可能抽到一个数值相当大的红包。理论上讲,加入前九个人运气都很差并都只抽到0.01,最后一个人抽取红包的数额可能接近100。当然,均匀分布下这类情况出现的可能性几乎为零,经过我反复验证,100,000次中都不会出现一次。我同时附上抽取红包的期望值大小以及标准差大小的表格。
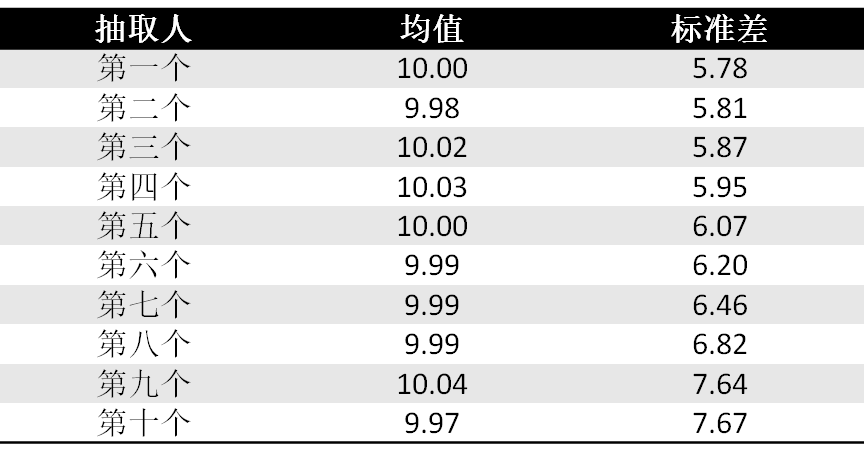

简单地说,结论就是:假设陈鹏先生贴的算法是可靠的,那么风险规避(risk-averse)的红包抽取人应该尽量抢先抽取,而风险偏爱(risk-seeking)的红包抽取人应该尽量后抽取(而且越往后似乎标准差增速也越大),因为后抽者取有可能抽到先抽取者不可能抽到的大红包,尽管抽到小红包的概率也会相应增大。Most of the things of this world are about trade-off, and there is just no such thing as a free lunch.
最后附上我发的两个红包所获取的原始数据,这样有兴趣的研究猿可以在我的基础上做进一步调查与研究。祝大家猴年吉祥,万事胜意!