









hadoop集群搭建至少3台以上节点,这里用VMware,虚拟出以5台centenOS6.5,
分别为:node01~node05(hostname)
1、基础配置
(1)配置好每台机器ip,修改hostname,配置dns
node01为master,node05作为 backup-master,node02、node03、node04作为slaves
node01、node02、node03上安装zookeeper
backup-master主要用于HA集群,会再后续文章中介绍。
配置ip,编辑vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
TYPE=Ethernet
UUID=5bb4cc10-358d-46b0-9714-ab58106fe502
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.1.71 #ip
NETMASK=255.255.255.0 #子网掩码
GATEWAY=192.168.1.2 #网关修改hostname,编辑 vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=node01配置dns,编辑vi /etc/resolv.conf
nameserver 8.8.8.8每台机器上都配置一下,配置完重启生效,当然如果你已经好了那就没必要了
(2)配置hosts,vim /etc/profile/hosts,加入
192.168.1.71 node01
192.168.1.72 node02
192.168.1.73 node03
192.168.1.74 node04
192.168.1.75 node05(3)ssh免密码登录
master、backup-master互相免密码登录,master、backup-master免密码登录slaves,同时每个节点实现自身免密码登录,具体参见:http://blog.csdn.net/lzxlfly/article/details/77916842
(4)配置jdk环境变量 (因为hadoop、hbase版本较高,采用jdk1.8)
vi /etc/profile ,加入以下内容
export JAVA_HOME=/usr/local/jdk1.8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH(5)安装ntp服务校正各个节点之间的时间一致
具体参见:http://blog.csdn.net/lzxlfly/article/details/78018595(6)端口太多,为了方便直接关闭防火墙
chkconfig iptables off 重启后生效service iptables stop 即时生效,重启后失效
2、hadoop安装配置
(1)配置hadoop环境变量
编辑vi /etc/profile ,添加以下内容
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.4 #hadoop安装路径
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
编辑vi /opt/hadoop/hadoop-2.7.4/etc/hadoop/hadoop-env.sh 添加以下内容
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk1.8 #jdk路径(2)配置相关xml
进入 cd /opt/hadoop/hadoop-2.7.4/etc/hadoop下,进行配置core-site.xml配置,默认文件core-default.xml在hadoop-common-2.5.1.jar中
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
<description>NameNode URI</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value><!--默认4096 bytes-->
<description>Size of read/write buffer used inSequenceFiles</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data</value><!--建议重新设置,默认路径重启集群后会失效-->
<description>A base for other temporary directories</description>
</property>
</configuration>hdfs-site.xml配置,默认文件hdfs-default.xml在hadoop-hdfs-2.5.1.jar中
<configuration>
<property>
<name>dfs.namenode.name.dir</name><!--这个属性可以省略,默认路径file:///${hadoop.tmp.dir}/dfs/name-->
<value>file:///data/dfs/name</value>
<description>Path on the local filesystem where the NameNodestores the namespace and transactions logs persistently</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node05:9868</value><!--secondaryNameNode设置在node05上,建议生产环境专门设置在一台机器上-->
<description>The secondary namenode http server address andport,默认port50090</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value><!--备份默认为3,不能超过datanode的数量-->
</property>
<property>
<name>dfs.datanode.data.dir</name><!--这个属性可以省略,默认路径file:///${hadoop.tmp.dir}/dfs/data-->
<value>file:///data/dfs/data</value>
<description>Comma separated list of paths on the local filesystemof a DataNode where it should store its blocks</description>
</property>
</configuration>mapred-site.xml配置,默认文件mapred-default.xml在hadoop-mapreduce-client-core-2.5.1.jar中
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value><!--这里设置为yarn框架,默认local-->
<description>The runtime framework for executing MapReduce jobs. Can be one of local, classic or yarn.</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
<description>MapReduce JobHistoryServer IPC host:port</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
<description>MapReduce JobHistoryServer Web UI host:port</description>
</property>
</configuration>yarn-site.xml配置,默认文件yarn-default.xml在hadoop-yarn-common-2.5.1.jar中
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
<description>The hostname of theRM</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Shuffle service that needs to be set for Map Reduceapplications</description>
</property>
</configuration>编辑vi slaves,去掉localhost,添加slaves节点
node02
node03
node04(3)将配置好的hadoop分发到其它节点对应目录下
scp -r /opt/hadoop/hadoop2.7.4 node02:`pwd`
scp -r /opt/hadoop/hadoop2.7.4 node03:`pwd`
scp -r /opt/hadoop/hadoop2.7.4 node04:`pwd`
scp -r /opt/hadoop/hadoop2.7.4 node05:`pwd`
(4)启动hadoop集群
启动前要先进行格式化文件系统,在主节点node01上输入:hdfs namenode -format,等待格式化完成无误后在node01上输入:start-all.sh启动hadoop,也可以start-dfs.sh、start-yarn.sh分别启动
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [node01]
node01: starting namenode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-namenode-node01.out
node03: starting datanode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-datanode-node03.out
node02: starting datanode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-datanode-node02.out
node04: starting datanode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-datanode-node04.out
Starting secondary namenodes [node05]
node05: starting secondarynamenode, logging to /opt/hadoop/hadoop-2.7.4/logs/hadoop-root-secondarynamenode-node05.out
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop/hadoop-2.7.4/logs/yarn-root-resourcemanager-node01.out
node02: starting nodemanager, logging to /opt/hadoop/hadoop-2.7.4/logs/yarn-root-nodemanager-node02.out
node03: starting nodemanager, logging to /opt/hadoop/hadoop-2.7.4/logs/yarn-root-nodemanager-node03.out
node04: starting nodemanager, logging to /opt/hadoop/hadoop-2.7.4/logs/yarn-root-nodemanager-node04.out待启动完成后,在node01~node05分别输入jps命令查看进程
node01 :NameNode、ResourceManager
node02~node04:DataNode、NodeManager
node05:SecondaryNameNode
出现这些进程表明hadoop集群基本启动成功
在浏览器输入http://node01:50070可查看集群状态
输入:stop-all.sh,停止hadoop集群,等待几秒便会停止
hadoop配置可参见http://hadoop.apache.org/docs/r2.7.4/hadoop-project-dist/hadoop-common/ClusterSetup.html
3、zookeeper安装配置
(1)配置zookeeper环境变量
编辑vi /etc/profile ,添加以下内容
export ZOOKEEPER_HOME=/opt/hadoop/zookeeper-3.4.10 #zookeeper安装路径
export PATH=$ZOOKEEPER_HOME/bin:$PATH(2)配置zoo.cfg
编辑 vi /opt/hadoop/zookeeper-3.4.10/conf/zoo.cfg,修改默认路径
dataDir=/data/zookeeper #默认路径为/tmp/zookeeper并添加以下内容,zookeeper集群的通信地址,端口
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888分别在node01、node02、node03上/data/zookeeper,即dataDir对应目录下建立myid文件,
文件内容分别为1、2、3,也即server对应的1、2、3
由于机器有限,和hadoop、hbase部署在一起了,生产环境最好把zookeeper部署到独立的机器上
zookeeper一般为奇数个,这是由其选举算法决定的。
(3)将配置好的zookeeper分发到其它节点对应路劲下
scp -r /opt/hadoop/zookeeper3.4.10 node01:`pwd`
scp -r /opt/hadoop/zookeeper3.4.10 node02:`pwd`
scp -r /opt/hadoop/zookeeper3.4.10 node03:`pwd`
(4)启动zookeeper集群
在node01、node02、node03上分别执行 zkServer.sh start 命令
ZooKeeper JMX enabled by default
Using config: /opt/hadoop/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED启动完成后,分别在三个节点上执行jps命令,
看到 QuorumPeerMain进程表明zookeeper启动成功。
在node01、node02、node03上分别执行 zkServer.sh status命令
node01显示:
ZooKeeper JMX enabled by default
Using config: /opt/hadoop/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
ZooKeeper JMX enabled by default
Using config: /opt/hadoop/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: followerZooKeeper JMX enabled by default
Using config: /opt/hadoop/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: leaderzookeeper部署可参见http://zookeeper.apache.org/doc/r3.4.10/zookeeperStarted.html
4、hbase安装配置
(1)配置hbase环境变量
编辑vi /etc/profile ,添加以下内容
export HBASE_HOME=/opt/hadoop/hbase-1.2.6 #hbase安装路径
export PATH=$HBASE_HOME/bin:$PATH去掉export前的注释,填写jdk路径
export JAVA_HOME=/usr/local/jdk1.8 #jdk路径去掉export前的注释,设置为false,不用hbase内置的zookeeper
export HBASE_MANAGES_ZK=false如果jdk1.8,还要注释以下两行
# Configure PermSize. Only needed in JDK7. You can safely remove it for JDK8+
#export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
#export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"若不注释的话,启动hbase会报以下警告,Java HotSpot(TM) 64-Bit Server VM warning。
starting master, logging to /opt/hadoop/hbase-1.2.6/logs/hbase-root-master-node01.out
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
node02: starting regionserver, logging to /opt/hadoop/hbase-1.2.6/bin/../logs/hbase-root-regionserver-node02.out
node03: starting regionserver, logging to /opt/hadoop/hbase-1.2.6/bin/../logs/hbase-root-regionserver-node03.out
node04: starting regionserver, logging to /opt/hadoop/hbase-1.2.6/bin/../logs/hbase-root-regionserver-node04.out
node02: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
node02: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
node03: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
node03: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
node04: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
node04: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
node05: starting master, logging to /opt/hadoop/hbase-1.2.6/bin/../logs/hbase-root-master-node05.out
node05: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
node05: Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
(2)配置hbase-site.xml
配置hbase-site.xml,默认文件hbase-site.xml在hbase-common-1.2.6.jar中
<configuration>
<property>
<name>hbase.rootdir</name> <!-- hbase存放数据目录 ,默认值${hbase.tmp.dir}/hbase-->
<value>hdfs://node01:9000/data/hbase_db</value><!-- 端口要和Hadoop的fs.defaultFS端口一致-->
</property>
<property>
<name>hbase.cluster.distributed</name> <!-- 是否分布式部署 -->
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name> <!-- list of zookooper -->
<value>node01,node02,node03</value>
</property>
</configuration>(3)配置regionservers、backup-masters
vi regionservers,去掉localhost,添加slaves节点
node02
node03
node04backup-masters不存在,需要手动创建并添加备份节点
node05 #可以有多个,一般一个备份就够了(4)把hadoop的hdfs-site.xml复制一份到hbase的conf目录下
因为hbase的数据最终要写入hdfs中,要把hbase的路径链接到hsfs中
cp /opt/hadoop/hadoop2.7.4/etc/haddop/hdfs-site.xml /opt/hadoop/hbase-1.2.6/conf(5)将配置好的hbase分发到其它节点
scp -r /opt/hadoop/hbase1.2.6 node02:`pwd`
scp -r /opt/hadoop/hbase1.2.6 node03:`pwd`
scp -r /opt/hadoop/hbase1.2.6 node04:`pwd`
scp -r /opt/hadoop/hbase1.2.6 node05:`pwd(6)启动hbase集群
在node01上输入:start-hbase.sh,hbase会开始启动
starting master, logging to /opt/hadoop/hbase-1.2.6/logs/hbase-root-master-node01.out
node02: starting regionserver, logging to /opt/hadoop/hbase-1.2.6/bin/../logs/hbase-root-regionserver-node02.out
node03: starting regionserver, logging to /opt/hadoop/hbase-1.2.6/bin/../logs/hbase-root-regionserver-node03.out
node04: starting regionserver, logging to /opt/hadoop/hbase-1.2.6/bin/../logs/hbase-root-regionserver-node04.out
node05: starting master, logging to /opt/hadoop/hbase-1.2.6/bin/../logs/hbase-root-master-node05.out等待启动完成,在每个节点上输入jps命令,查看进程
node01,node05:HMaster、
node02~node04:HRegionServer
出现以上进程表hbase明启动成功了
在浏览器输入http://node01:16010 可查看hbase集群状态
在node01上输入:stop-hbase.sh,hbase集群会等待几秒就会停止了
hbase配置可参见:http://hbase.apache.org/book.html#_introduction
5、注意事项及常见问题
(1)每个节点上目录以及文件路径都要相同
(2)hadoop格式化问题
执行hadoop namenode -format 格式化一般首次执行就行了。
若要重新格式化,首先,停止集群,删除namenode和datanode对应的持久化数据存储目录,再格式化新文件系统。
因为重新格式化,namenode的数据会重新生成,datanode的数据不会重新生成,仍是原来的数据,
这样namenode和datanode不在一个集群,从而导致datanode启动不成功。
(3)hbase环境变量配置问题
hbase环境变量配置出错,会出现以下问题:
Error: Could not find or load main class org.apache.hadoop.hbase.util.HBaseConfTool
Error: Could not find or load main class org.apache.hadoop.hbase.zookeeper.ZKServerTool
starting master, logging to /opt/hadoop/zookeeper-3.4.10/logs/hbase-root-master-node01.out
nice: /opt/hadoop/zookeeper-3.4.10/bin/hbase: No such file or directory
cat: /opt/hadoop/zookeeper-3.4.10/conf/regionservers: No such file or directory
cat: /opt/hadoop/zookeeper-3.4.10/conf/regionservers: No such file or directory
出现这个问题一般都是hbase环境变量配置出错了,请认真检查环境变量配置
(4)hadoop、hbase、jdk的版本要匹配,
hadoop与jdk,hadoop2.7要求jdk7以上
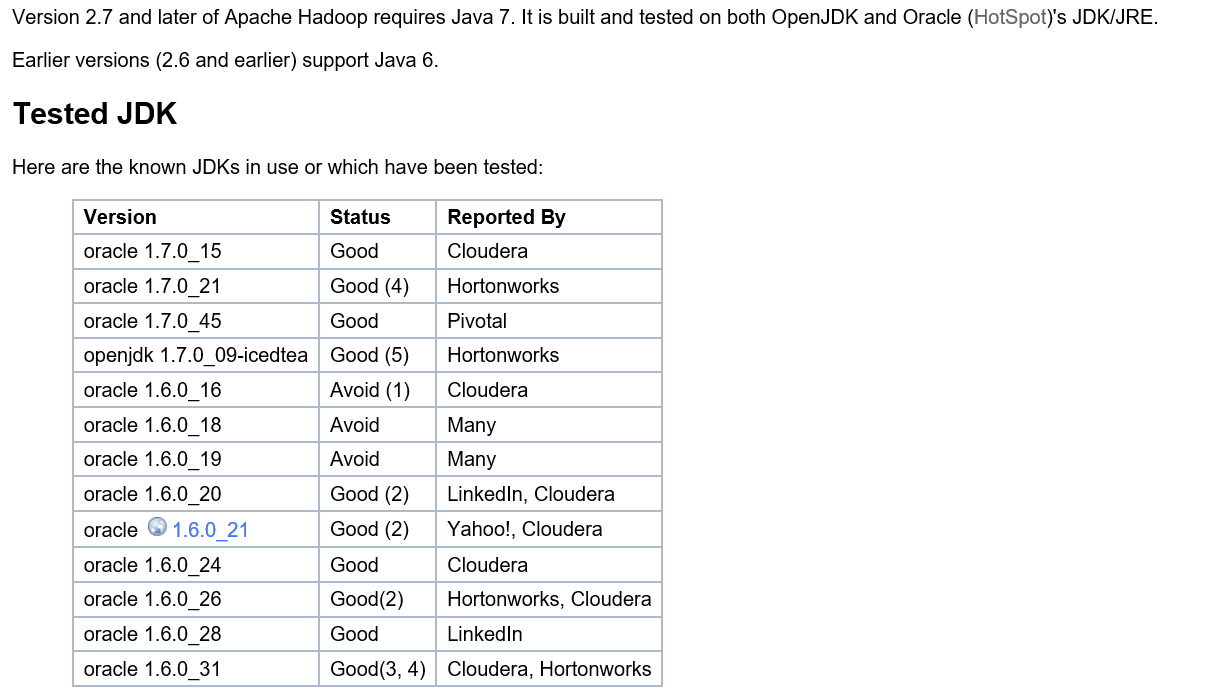
hbase与jdk对照
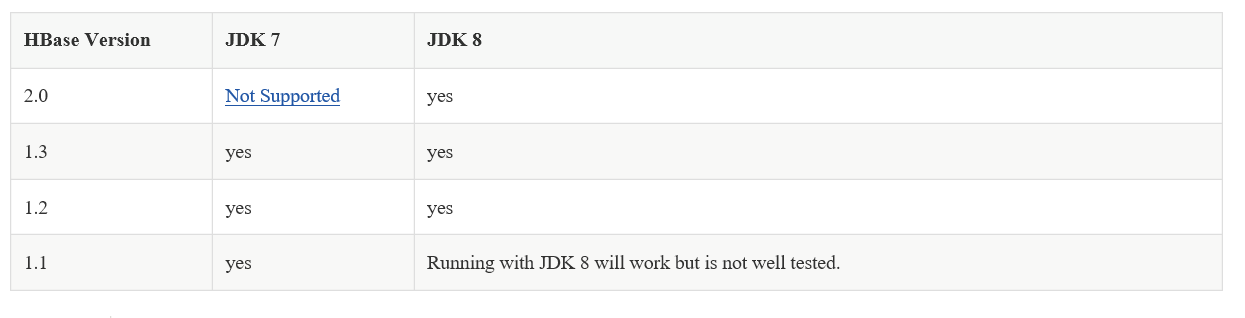
hadoop与hbase对照
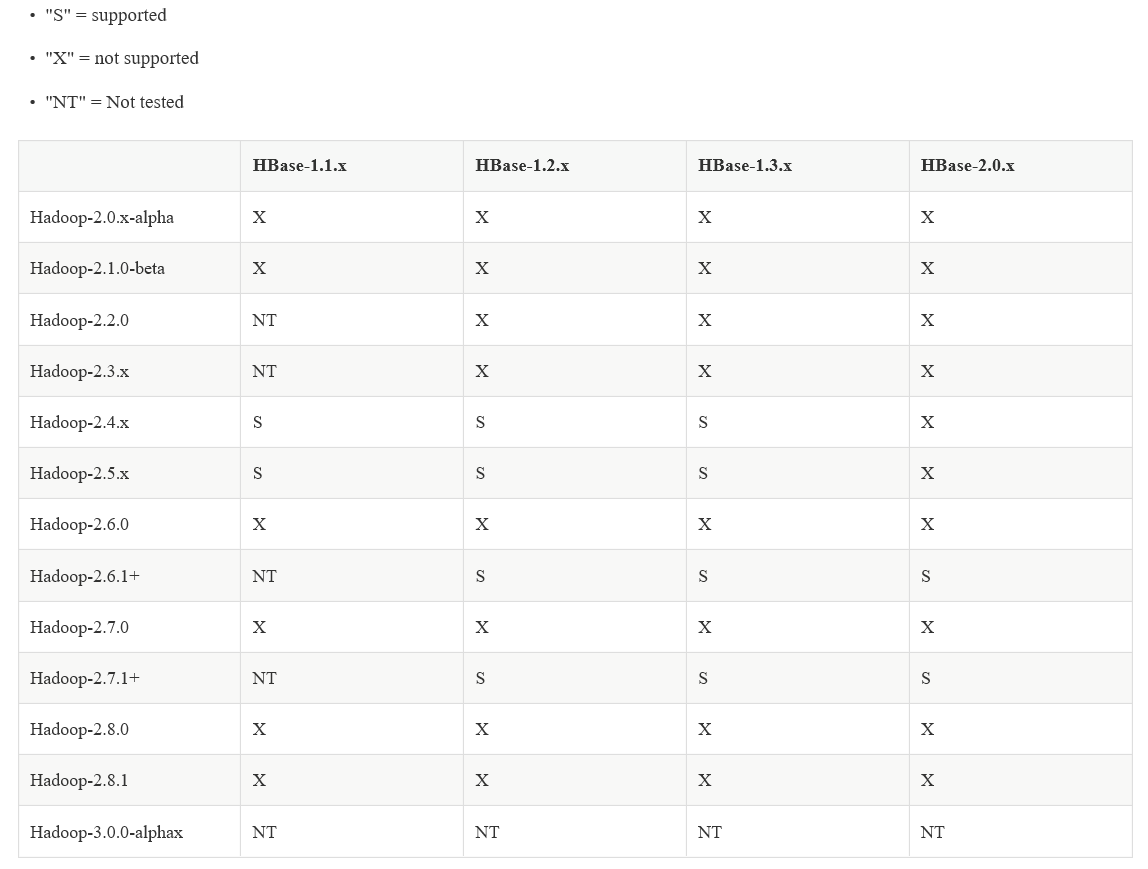
而hase1.2.x要求zookeeper3.4.x以上














 4314
4314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









