实际上是反反爬的技术,我对 JS 代码了解不多,看得头晕,有人会么?教教我,或者有教程之类的也行.
针对的机制的 crawlerInfo 加密函数,我找来找去,越来越乱,特此求助!
实际上是反反爬的技术,我对 JS 代码了解不多,看得头晕,有人会么?教教我,或者有教程之类的也行.
针对的机制的 crawlerInfo 加密函数,我找来找去,越来越乱,特此求助!
我们很熟悉爬虫,爬虫存在互联网的各个角落,爬虫有好处也有坏处,今天我们不讲如何进行爬取,我们来说一说和爬虫共同诞生的反爬虫技术。爬虫技术造成的大量 IP 访问网站侵占带宽资源、以及用户隐私和知识产权等危害,很多互联网企业都会花大力气进行“反爬虫”。相比于爬虫技术,反爬虫其实更复杂。在 90 年代开始有搜索引擎网站利用爬虫技术抓取网站时,一些搜索引擎从业者和网站站长通过邮件讨论定下了一项“君子协议”—— robots.txt。即网站有权规定网站中哪些内容可以被爬虫抓取,哪些内容不可以被爬虫抓取。这样既可以保护隐私和敏感信息,又可以被搜索引擎收录、增加流量。在远古时期,互联网还是一片乐土,大多数从业者都会默守这一协定,毕竟那时候信息和数据都没什么油水可捞。但很快互联网上开始充斥着商品信息、机票价格、个人隐私等等,在利益的诱惑下,自然有些人会开始违法爬虫协议了。当君子协议不再有效时,我们就采取技术的手段来反爬虫,今天我们主要说一说有那些技术方法来应对爬虫进行反爬。
**01
**
通过请求头来控制访问
不管是浏览器还是爬虫程序,在访问目标源网站时都会带上一个头文件:User-Agent
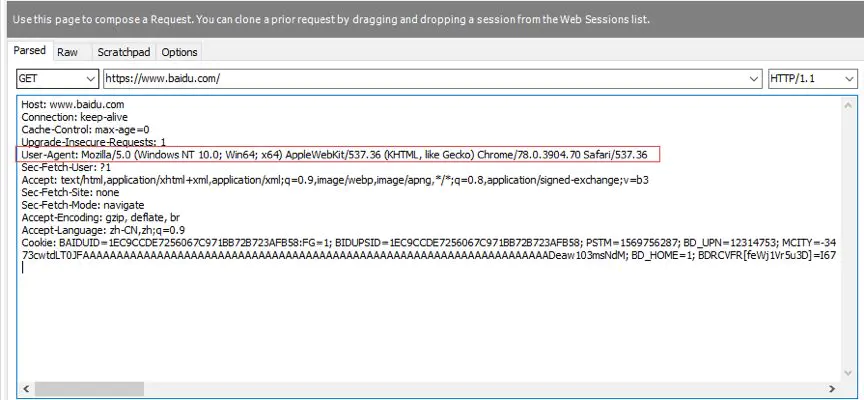
**反爬策略:**我们的网站可以设定 User-Agent 白名单,属于正常的范围才能访问
**缺点:**爬虫程序很容易伪造头部进行请求,只能拦截一部分新手爬虫。
**02
**
ip 限制
**反爬策略:**让一个固定的 ip 在短时间,不能对接口进行频繁访问。
**缺点:**爬虫程序可以通过 ip 代理池切换 ip 进行访问,但对爬虫者来讲需要一定成本,对于反爬虫来讲通过这种免费或付费的 ip 代理可以绕过检测。
*代理ip池实现的简单思路*@return*/public static Sting getProxy(){String [] proxy={“http://118.245.23.2:80”,“http://118.145.23.2:8118”,“http://117.245.23.2:88”,“http://116.245.23.2:80”};return proxy [new Random().nextInt(proxy.length)];}
**03
**
验证码验证
验证码是一种区分用户是计算机还是人的公共全自动程序。可以防止:恶意破解密码、刷票、论坛灌水,有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试,实际上用验证码是现在很多网站通行的方式,我们利用比较简易的方式实现了这个功能。这个问题可以由计算机生成并评判,但是必须只有人类才能解答。由于 计算机无法解答 CAPTCHA 的问题,所以回答出问题的用户就可以被认为是人类。


**缺点:**影响正常的用户体验操作,验证码越复杂,网站体验感越差
**04
**
session 访问限制
**反爬措施:**后台统计登录用户的操作,比如短时间的点击事件,请求数据事件,与正常值比对,用于区分用户是否处理异常状态,如果是,则限制登录用户操作权限。
**缺点:**需要增加数据埋点功能,阈值设置不好,容易误杀。
**05
**
数据加密
**反爬措施:**前端可以通过对查询参数、user-agent、验证码、cookie 等前端数据进行加密生成一串加密指令,将加密指令作为参数,再进行服务器数据请求。该加密参数为空或者错误,服务器都不对请求进行响应;后端可以在服务器端同样有一段加密逻辑,生成一串编码,与请求的编码进行匹配,匹配通过则会返回数据。
**缺点:**加密算法写在 JS 里,爬虫程序经过一系列分析还是可以进行破解。
**06
**
但是目前面对这些反爬虫技术,如果我们为了获取数据又必须用爬虫技术,那么面对这种情况应该如何解决?
首先我先介绍Google Chrome的开发者工具的打开方式,我下面的介绍都是在Google Chrome里进行,所以这个开发者工具的使用比较重要。
首先打开Google Chrome,对于Mac而言Cmd+Opt+I Windows而言Ctrl+Shift+I
以此我们可以打开开发者工具
我们就以知乎为例进行解释
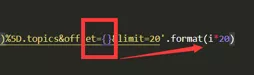
打开开发者工具之后,根据上图的步骤我们可以找到需要使用的网址。
然后在 Atom 里可以输入以下代码,从而形成一个 python 的文件。
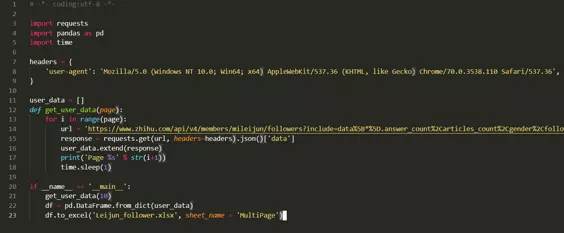
从而可以将数据爬取出来
七牛云是国内领先的企业级公有云服务商,致力于打造以数据为核心的场景化 PaaS 服务。围绕富媒体场景,七牛先后推出了对象存储,融合 CDN 加速,数据通用处理,内容反垃圾服务,以及直播云服务等。
找到自己的位置,萌新烦恼少。
Google App Engine(GAE)是 Google 管理的数据中心中用于 WEB 应用程序的开发和托管的平台。2008 年 4 月 发布第一个测试版本。目前支持 Python、Java 和 Go 开发部署。全球已有数十万的开发者在其上开发了众多的应用。
jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据。
昆明尊园房地产经纪有限公司,即:Kunming Zunyuan Property Agency Company Limited(简称“尊园地产”)于 2007 年 6 月开始筹备,2007 年 8 月 18 日正式成立,注册资本 200 万元,公司性质为股份经纪有限公司,主营业务为:代租、代售、代办产权过户、办理银行按揭、担保、抵押、评估等。
域名(Domain Name),简称域名、网域,是由一串用点分隔的名字组成的 Internet 上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的电子方位(有时也指地理位置)。
你比 99% 的人都优秀么?
沉迷游戏伤身,强撸灰飞烟灭。
设计模式(Design pattern)代表了最佳的实践,通常被有经验的面向对象的软件开发人员所采用。设计模式是软件开发人员在软件开发过程中面临的一般问题的解决方案。这些解决方案是众多软件开发人员经过相当长的一段时间的试验和错误总结出来的。
MyBatis 本是 Apache 软件基金会 的一个开源项目 iBatis,2010 年这个项目由 Apache 软件基金会迁移到了 google code,并且改名为 MyBatis ,2013 年 11 月再次迁移到了 GitHub。
红帽提供的 PaaS 云,支持多种编程语言,为开发人员提供了更为灵活的框架、存储选择。
CSS(Cascading Style Sheet)“层叠样式表”是用于控制网页样式并允许将样式信息与网页内容分离的一种标记性语言。
MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于 Oracle 公司。MySQL 是最流行的关系型数据库管理系统之一。
如果帖子标签含有 Sandbox ,则该帖子会被视为“测试帖”,主要用于测试社区功能,排查 bug 等,该标签下内容不定期进行清理。
CAP 指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可兼得。
Kubernetes 是 Google 开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。
MongoDB(来自于英文单词“Humongous”,中文含义为“庞大”)是一个基于分布式文件存储的数据库,由 C++ 语言编写。旨在为应用提供可扩展的高性能数据存储解决方案。MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似 JSON 的 BSON 格式,因此可以存储比较复杂的数据类型。
C++ 是在 C 语言的基础上开发的一种通用编程语言,应用广泛。C++ 支持多种编程范式,面向对象编程、泛型编程和过程化编程。
脑图又叫思维导图,是表达发散性思维的有效图形思维工具 ,它简单却又很有效,是一种实用性的思维工具。
etcd 是一个分布式、高可用的 key-value 数据存储,专门用于在分布式系统中保存关键数据。
JetBrains 是一家捷克的软件开发公司,该公司位于捷克的布拉格,并在俄国的圣彼得堡及美国麻州波士顿都设有办公室,该公司最为人所熟知的产品是 Java 编程语言开发撰写时所用的集成开发环境:IntelliJ IDEA。
Telegram 是一个非盈利性、基于云端的即时消息服务。它提供了支持各大操作系统平台的开源的客户端,也提供了很多强大的 APIs 给开发者创建自己的客户端和机器人。
InfluxDB 是一个开源的没有外部依赖的时间序列数据库。适用于记录度量,事件及实时分析。
Ngui 是一个 GUI 的排版显示引擎和跨平台的 GUI 应用程序开发框架,基于
Node.js / OpenGL。目标是在此基础上开发 GUI 应用程序可拥有开发 WEB 应用般简单与速度同时兼顾 Native 应用程序的性能与体验。

欢迎来到这里!
我们正在构建一个小众社区,大家在这里相互信任,以平等 • 自由 • 奔放的价值观进行分享交流。最终,希望大家能够找到与自己志同道合的伙伴,共同成长。
注册 关于