实际上是反反爬的技术,我对 JS 代码了解不多,看得头晕,有人会么?教教我,或者有教程之类的也行.
针对的机制的 crawlerInfo 加密函数,我找来找去,越来越乱,特此求助!
实际上是反反爬的技术,我对 JS 代码了解不多,看得头晕,有人会么?教教我,或者有教程之类的也行.
针对的机制的 crawlerInfo 加密函数,我找来找去,越来越乱,特此求助!
我们很熟悉爬虫,爬虫存在互联网的各个角落,爬虫有好处也有坏处,今天我们不讲如何进行爬取,我们来说一说和爬虫共同诞生的反爬虫技术。爬虫技术造成的大量 IP 访问网站侵占带宽资源、以及用户隐私和知识产权等危害,很多互联网企业都会花大力气进行“反爬虫”。相比于爬虫技术,反爬虫其实更复杂。在 90 年代开始有搜索引擎网站利用爬虫技术抓取网站时,一些搜索引擎从业者和网站站长通过邮件讨论定下了一项“君子协议”—— robots.txt。即网站有权规定网站中哪些内容可以被爬虫抓取,哪些内容不可以被爬虫抓取。这样既可以保护隐私和敏感信息,又可以被搜索引擎收录、增加流量。在远古时期,互联网还是一片乐土,大多数从业者都会默守这一协定,毕竟那时候信息和数据都没什么油水可捞。但很快互联网上开始充斥着商品信息、机票价格、个人隐私等等,在利益的诱惑下,自然有些人会开始违法爬虫协议了。当君子协议不再有效时,我们就采取技术的手段来反爬虫,今天我们主要说一说有那些技术方法来应对爬虫进行反爬。
**01
**
通过请求头来控制访问
不管是浏览器还是爬虫程序,在访问目标源网站时都会带上一个头文件:User-Agent
**反爬策略:**我们的网站可以设定 User-Agent 白名单,属于正常的范围才能访问
**缺点:**爬虫程序很容易伪造头部进行请求,只能拦截一部分新手爬虫。
**02
**
ip 限制
**反爬策略:**让一个固定的 ip 在短时间,不能对接口进行频繁访问。
**缺点:**爬虫程序可以通过 ip 代理池切换 ip 进行访问,但对爬虫者来讲需要一定成本,对于反爬虫来讲通过这种免费或付费的 ip 代理可以绕过检测。
*代理ip池实现的简单思路*@return*/public static Sting getProxy(){String [] proxy={“http://118.245.23.2:80”,“http://118.145.23.2:8118”,“http://117.245.23.2:88”,“http://116.245.23.2:80”};return proxy [new Random().nextInt(proxy.length)];}
**03
**
验证码验证
验证码是一种区分用户是计算机还是人的公共全自动程序。可以防止:恶意破解密码、刷票、论坛灌水,有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试,实际上用验证码是现在很多网站通行的方式,我们利用比较简易的方式实现了这个功能。这个问题可以由计算机生成并评判,但是必须只有人类才能解答。由于 计算机无法解答 CAPTCHA 的问题,所以回答出问题的用户就可以被认为是人类。


**缺点:**影响正常的用户体验操作,验证码越复杂,网站体验感越差
**04
**
session 访问限制
**反爬措施:**后台统计登录用户的操作,比如短时间的点击事件,请求数据事件,与正常值比对,用于区分用户是否处理异常状态,如果是,则限制登录用户操作权限。
**缺点:**需要增加数据埋点功能,阈值设置不好,容易误杀。
**05
**
数据加密
**反爬措施:**前端可以通过对查询参数、user-agent、验证码、cookie 等前端数据进行加密生成一串加密指令,将加密指令作为参数,再进行服务器数据请求。该加密参数为空或者错误,服务器都不对请求进行响应;后端可以在服务器端同样有一段加密逻辑,生成一串编码,与请求的编码进行匹配,匹配通过则会返回数据。
**缺点:**加密算法写在 JS 里,爬虫程序经过一系列分析还是可以进行破解。
**06
**
但是目前面对这些反爬虫技术,如果我们为了获取数据又必须用爬虫技术,那么面对这种情况应该如何解决?
首先我先介绍Google Chrome的开发者工具的打开方式,我下面的介绍都是在Google Chrome里进行,所以这个开发者工具的使用比较重要。
首先打开Google Chrome,对于Mac而言Cmd+Opt+I Windows而言Ctrl+Shift+I
以此我们可以打开开发者工具
我们就以知乎为例进行解释
打开开发者工具之后,根据上图的步骤我们可以找到需要使用的网址。
然后在 Atom 里可以输入以下代码,从而形成一个 python 的文件。
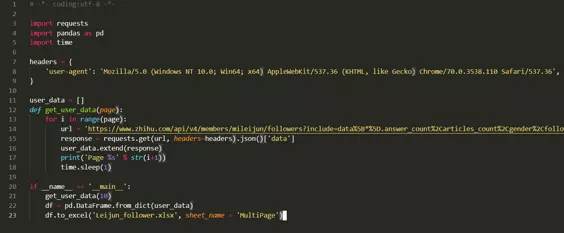
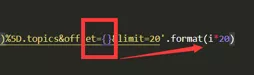
从而可以将数据爬取出来
你若安好,便是晴天。
Git 是 Linux Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的操作系统上。容器完全使用沙箱机制,几乎没有性能开销,可以很容易地在机器和数据中心中运行。
flomo 是新一代 「卡片笔记」 ,专注在碎片化时代,促进你的记录,帮你积累更多知识资产。
智能合约(Smart contract)是一种旨在以信息化方式传播、验证或执行合同的计算机协议。智能合约允许在没有第三方的情况下进行可信交易,这些交易可追踪且不可逆转。智能合约概念于 1994 年由 Nick Szabo 首次提出。
宕机,多指一些网站、游戏、网络应用等服务器一种区别于正常运行的状态,也叫“Down 机”、“当机”或“死机”。宕机状态不仅仅是指服务器“挂掉了”、“死机了”状态,也包括服务器假死、停用、关闭等一些原因而导致出现的不能够正常运行的状态。
Hadoop 是由 Apache 基金会所开发的一个分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
阿里巴巴网络技术有限公司(简称:阿里巴巴集团)是以曾担任英语教师的马云为首的 18 人,于 1999 年在中国杭州创立,他们相信互联网能够创造公平的竞争环境,让小企业通过创新与科技扩展业务,并在参与国内或全球市场竞争时处于更有利的位置。
Markdown 是一种轻量级标记语言,用户可使用纯文本编辑器来排版文档,最终通过 Markdown 引擎将文档转换为所需格式(比如 HTML、PDF 等)。
Python 是一种面向对象、直译式电脑编程语言,具有近二十年的发展历史,成熟且稳定。它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务。它的语法简捷和清晰,尽量使用无异义的英语单词,与其它大多数程序设计语言使用大括号不一样,它使用缩进来定义语句块。
Cloud Foundry 是 VMware 推出的业界第一个开源 PaaS 云平台,它支持多种框架、语言、运行时环境、云平台及应用服务,使开发人员能够在几秒钟内进行应用程序的部署和扩展,无需担心任何基础架构的问题。
小薇是一个用 Java 写的 QQ 聊天机器人 Web 服务,可以用于社群互动。
由于 Smart QQ 从 2019 年 1 月 1 日起停止服务,所以该项目也已经停止维护了!
支付宝是全球领先的独立第三方支付平台,致力于为广大用户提供安全快速的电子支付/网上支付/安全支付/手机支付体验,及转账收款/水电煤缴费/信用卡还款/AA 收款等生活服务应用。
子曰:“工欲善其事,必先利其器。”
1999 年 2 月腾讯正式推出“腾讯 QQ”,在线用户由 1999 年的 2 人(马化腾和张志东)到现在已经发展到上亿用户了,在线人数超过一亿,是目前使用最广泛的聊天软件之一。
Latke 是一款以 JSON 为主的 Java Web 框架。
Hexo 是一款快速、简洁且高效的博客框架,使用 Node.js 编写。
CSS(Cascading Style Sheet)“层叠样式表”是用于控制网页样式并允许将样式信息与网页内容分离的一种标记性语言。
Java 是一种可以撰写跨平台应用软件的面向对象的程序设计语言,是由 Sun Microsystems 公司于 1995 年 5 月推出的。Java 技术具有卓越的通用性、高效性、平台移植性和安全性。
Linux 是一套免费使用和自由传播的类 Unix 操作系统,是一个基于 POSIX 和 Unix 的多用户、多任务、支持多线程和多 CPU 的操作系统。它能运行主要的 Unix 工具软件、应用程序和网络协议,并支持 32 位和 64 位硬件。Linux 继承了 Unix 以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。
MongoDB(来自于英文单词“Humongous”,中文含义为“庞大”)是一个基于分布式文件存储的数据库,由 C++ 语言编写。旨在为应用提供可扩展的高性能数据存储解决方案。MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似 JSON 的 BSON 格式,因此可以存储比较复杂的数据类型。
Mobi.css is a lightweight, flexible CSS framework that focus on mobile.
据说 99% 的性能瓶颈都在数据库。
房星网,我们不和没有钱的程序员谈理想,我们要让程序员又有理想又有钱。我们有雄厚的房地产行业线下资源,遍布昆明全城的 100 家门店、四千地产经纪人是我们坚实的后盾。
WiFiDog 是一套开源的无线热点认证管理工具,主要功能包括:位置相关的内容递送;用户认证和授权;集中式网络监控。

欢迎来到这里!
我们正在构建一个小众社区,大家在这里相互信任,以平等 • 自由 • 奔放的价值观进行分享交流。最终,希望大家能够找到与自己志同道合的伙伴,共同成长。
注册 关于