基于 golang 1.9
本文主要包括 map 的基本数据数据结构和平时可能碰到的一些坑
map 的基本数据结构
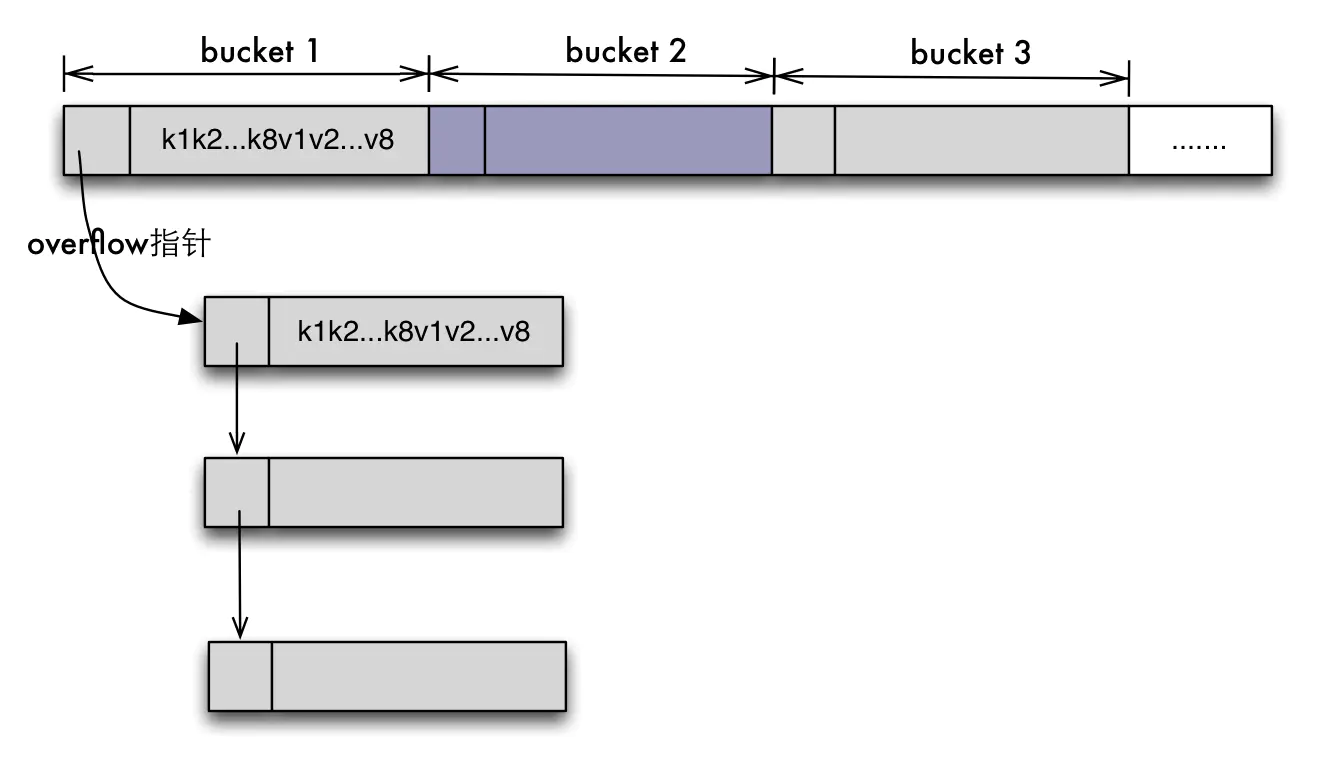
map 的底层机构是 hmap(hashmap) , 无法对 key 值排序遍历,核心元素是一由若干个桶(bucket,结构为 bmap)组成的数组,每个 bucket 可以存放若干个元素(通常是 8 个),key 通过哈希算法被归入到不同的 bucket 中。当超过 8 个元素需要存入 bucket 中时,hmap 会使用 extra 中的 overflow 来扩展该 bucket。下面是 hmap 的结构体
// A header for a Go map.
type hmap struct {
// Note: the format of the Hmap is encoded in ../../cmd/internal/gc/reflect.go and
// ../reflect/type.go. Don't change this structure without also changing that code!
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
在 extra 中不仅有 overflow,用于扩容和 nextoverflow(prealloc 的地址)。
bucket(bmap)的结构如下
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt values.
// NOTE: packing all the keys together and then all the values together makes the
// code a bit more complicated than alternating key/value/key/value/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
- tophash 用于记录 8 个 key 哈希值的高八位,这样在寻找对应 key 的时候可以更快,不必每次都对 key 做全值判断
- Note:hmap 并非只有一个 tophash,而是后面紧跟 8 组 kv 对和一个 overflow 的指针,这样才能使 overflow 成为一个链表结构。但是这两个结构体并不是显示定义的,而是直接通过指针运算进行访问的。
- kv 的存储形式为"key0key1key2key3...key7val1val2...val7",这样做的好处是:在 key 和 value 的长度不同的时候,节省 padding 空间。如上面的例子:在 map[int64]int8 中,4 个相邻的 int8
存储在同一个内存单元中。如果使用 kv 交错存储的话,每个 int8 都会被 padding 占用独自的内存单元(为了提高寻址速度)
Hmap 示意图
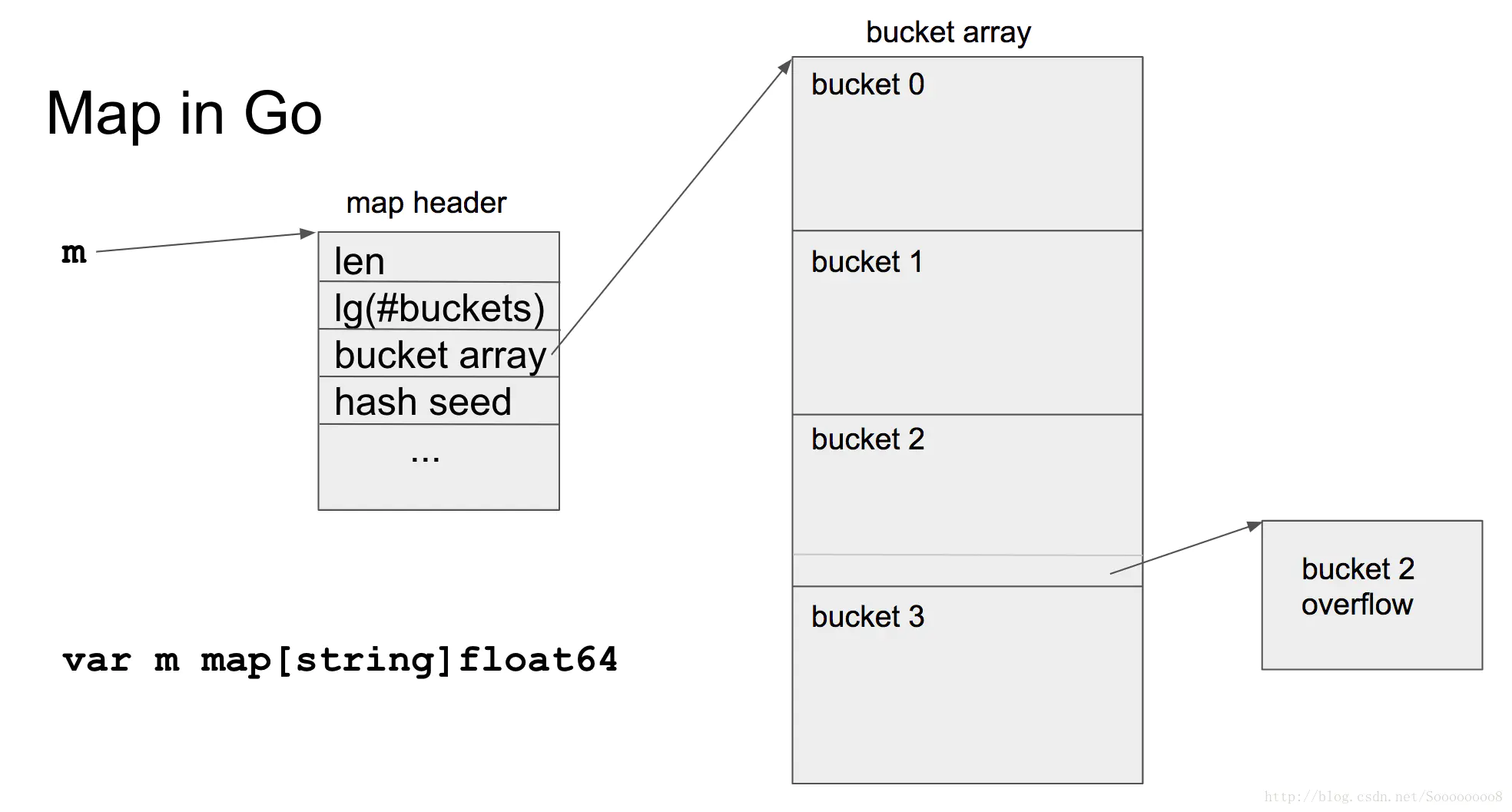
map 的访问
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// do some race detect things
// do some memory sanitizer thins
if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0])
}
if h.flags&hashWriting != 0 { // 检测是否并发写,map不是gorountine安全的
throw("concurrent map read and map write")
}
alg := t.key.alg // 哈希算法 alg -> algorithm
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// 如果老的bucket没有被移动完,那么去老的bucket中寻找 (增长部分下一节介绍)
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
// 寻找过程:不断比对tophash和key
top := tophash(hash)
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey {
k = *((*unsafe.Pointer)(k))
}
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
if t.indirectvalue {
v = *((*unsafe.Pointer)(v))
}
return v
}
}
}
return unsafe.Pointer(&zeroVal[0]
map 存值
首先用 key 的 hash 值低 8 位找到 bucket,然后在 bucket 内部比对 tophash 和高 8 位与其对应的 key 值与入参 key 是否相等,若找到则更新这个值。若 key 不存在,则 key 优先存入在查找的过程中遇到的空的 tophash 数组位置。若当前的 bucket 已满则需要另外分配空间给这个 key,新分配的 bucket 将挂在 overflow 链表后。
map 的增长
随着元素的增加,在一个 bucket 链中寻找特定的 key 会变得效率低下,所以在插入的元素个数/bucket 个数达到某个阈值(6.5)时候,map 会进行扩容,hashGrow 函数。首先创建 bucket 数组,长度为原长度的两倍 newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger),然后替换原有的 bucket,原有的 bucket 被移动到 oldbucket 指针下。
扩容完成后,每个 hash 对应两个 bucket(一个新的一个旧的)。oldbucket 不会立即被转移到新的 bucket 下,而是当访问到该 bucket 时,会调用 growWork 方法进行迁移,growWork 方法会将 oldbucket 下的元素 rehash 到新的 bucket 中。随着访问的进行,所有 oldbucket 会被逐渐移动到 bucket 中。
但是这里有个问题:如果需要进行扩容的时候,上一次扩容后的迁移还没结束,怎么办?在代码中我们可以看到很多”again”标记,会不断进行迁移,知道迁移完成后才会进行下一次扩容。
这个迁移并没有在扩容之后一次性完成,而是逐步完成的,每一次 insert 或 remove 时迁移 1 到 2 个 pair,即增量扩容。
增量扩容的原因 主要是缩短 map 容器的响应时间。若 hashmap 很大扩容时很容易导致系统停顿无响应。增量扩容本质上就是将总的扩容时间分摊到了每一次 hash 操作上。
由于这个工作是逐渐完成的,导致数据一部分在 old table 中一部分在 new table 中。old 的 bucket 不会删除,只是加上一个已删除的标记。只有当所有的 bucket 都从 old table 里迁移后才会将其释放掉
使用时候的问题
Q:删除掉 map 中的元素是否会释放内存?
A:不会,删除操作仅仅将对应的 tophash[i]设置为 empty,并非释放内存。若要释放内存只能等待指针无引用后被系统 gc
Q:如何并发地使用 map?
A:map 不是 goroutine 安全的,所以在有多个 gorountine 对 map 进行写操作是会 panic。多 gorountine 读写 map 是应加锁(RWMutex),或使用 sync.Map。
Q:map 的 iterator 是否安全?
A:map 的 delete 并非真的 delete,所以对迭代器是没有影响的,是安全的。
map 值得注意的地方
1、delete map 存在内存泄漏的问题
解决办法:定期更换成新的 map,释放旧的 map 对象
2、并发操作 map panic 不能被 recover 捕获
解决办法:加 sync.RWMutex 锁,或者使用 ConcurrentMap 组件
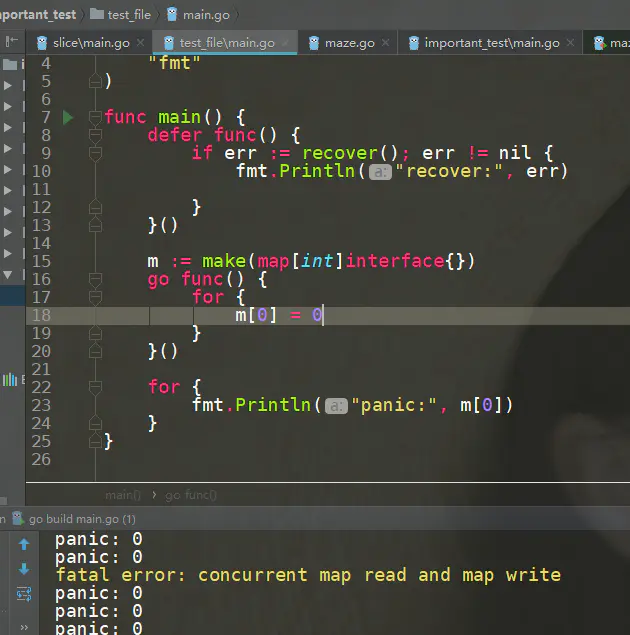
如图看到 recover 没有捕获到
3、每次 map 遍历不能得到相同排序的集合
4、map 的 key 不支持 slice,map,func,
5、map 是引用类型
欢迎来到这里!
我们正在构建一个小众社区,大家在这里相互信任,以平等 • 自由 • 奔放的价值观进行分享交流。最终,希望大家能够找到与自己志同道合的伙伴,共同成长。
注册 关于