author:yudake
1/17/2018 3:23:04 PM
英文原文: Understanding Convolutional Neural Networks for NLP(有删减)
我将文章中的模型应用在色情文章检测项目中,取得了 98% 以上的准确率。
github:色情文章检测
怎样在 NLP 中应用 CNN
与 CV 不同,在 NLP 中输入的不是图像像素,而是用矩阵表示的句子或文档。矩阵的每一行对应一个标记,通常是一个单词或者一个符号。
也就是说,每一行都是代表一个单词的行向量。
这一个向量就是 词嵌入 (一种低维矩阵表示),像 word2vec 或者 GloVe。或者可以用 one-hot 向量 将单词索引到词汇表。
比如,一个有 10 个单词的句子,我们把每个单词用 100 维的向量表示,我们就有了一个 10*100 的矩阵作为输入。这就是我们的“图片”。
在 CV 领域,filter 划过图像的部分区域(像素,典型的是 3*3),但是在 NLP 中,我们用 filter 划过矩阵的整行,并且跨越多行。也就是一个 filter 提取的特征是多个单词的特征。因此,我们 filter 的宽度就是矩阵的宽度。而 filter 的高度,或者说区域大小,是一个范围,一般是 2-5 个单词。
综上所述,一个用于 NLP 的 CNN 可能看起来如下图所示:
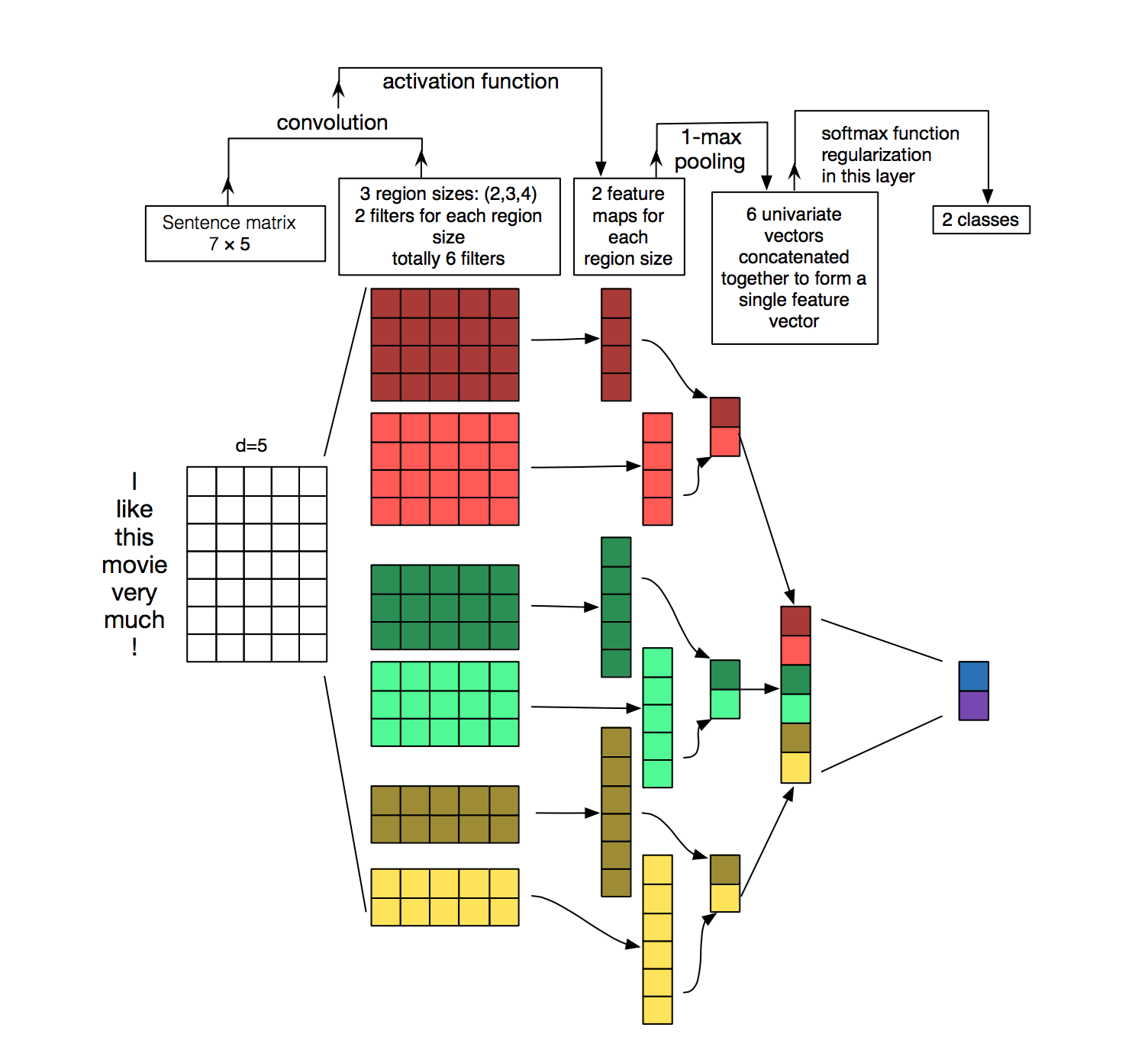
图 1:这里给了三种 filter 型号:2,3 和 4。每一种型号都有两个 filter。每一种 filter 卷积之后生成特征图。然后,对每一个特征图进行最大池化,然后将每个特征图池化后的特征进行拼接,生成一个 6*1 的列向量。最后将特征向量送入 softmax 层,这里假设输出有两种可能状态。 Source: Zhang, Y., & Wallace, B. (2015). A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification.
在 CV 中,位置不变性和局部合成对于图像来说很容易理解,但对 NLP 来说并不是这样。我们很关心某一单词出现在句子中的位置。图像中,邻近的像素可能在语义上是相关的,但对于单词并不总是这样。在一些语言中,一部分短语可以被其他单词分开。而且组成成分也不明显。显然的是,单词有一种方式进行组合,比如说形容词修饰名词,但是这种高级别的表示如何工作的并不像 CV 那样明显。
考虑到以上,CNN 似乎不太适合 NLP 任务。而 RNN 更加直观,就像人类处理语言的方式一样,从左往右依次阅读。
幸运的是,有些 CNN 模型是有用的。事实证明,应用于 NLP 问题的 CNN 表现相当不错。简单的 Bag of Words(词袋模型) 是一种显而易见的简化,这一简化并不精确,但是多年来一直是标准方法,并取得了不错的效果。
CNN 的一个主要优势就是速度快。CNN 的卷积可以在 GPU 上进行运算。即使与 N-grams 相比,CNN 在词汇表示方面也很有效。在大量词汇表下,计算超过 3-grams 是非常费时的,即使 Google 也不推荐超过 5-grams。卷积核可以自动学习好的表示方式,而不需要整个词汇表。完全可以设定 filter 的大小在 5 以上。
第一层的filter功能非常类似(但不限于)n-gram,但是以更简洁的方式表示
CNN 的超参数
宽卷积与窄卷积
窄卷积不使用零填充(如下左图)
宽卷积指的是在卷积时,使用零填充(如下右图)
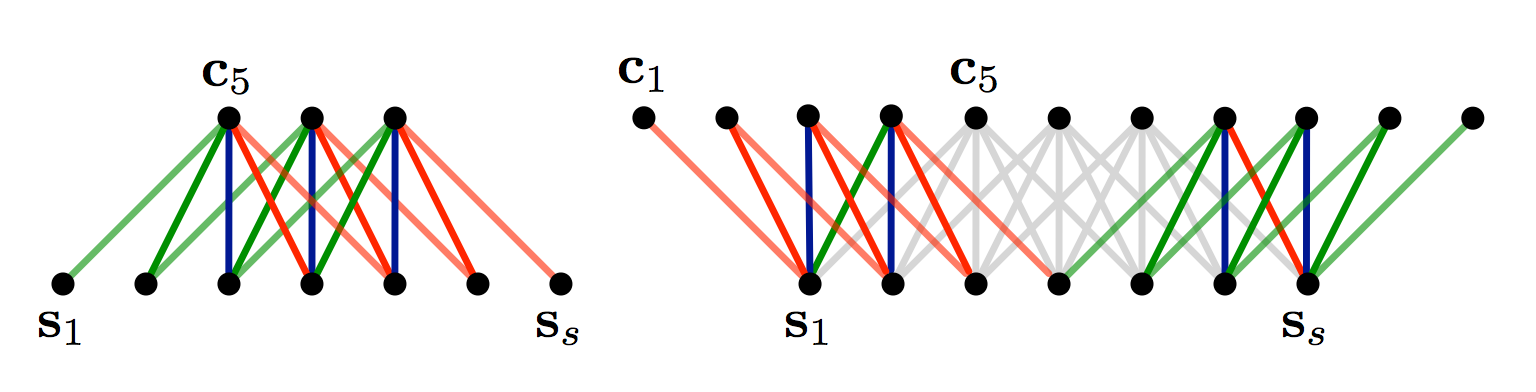
图 2:窄卷积与宽卷积。Filter size = 5, 输入 size = 7.
其中,窄卷积产生(7-5)+1=3 个输出。宽卷积产生(7+2*4-5)+1=11 个输出。
n_out = (n_in+2*n_padding-n_filter)+1
步长
步长(stride)定义每一步 filter 移动的数量。上面的所有步长都是 1。一维输入的步长一般是 1 或 2。
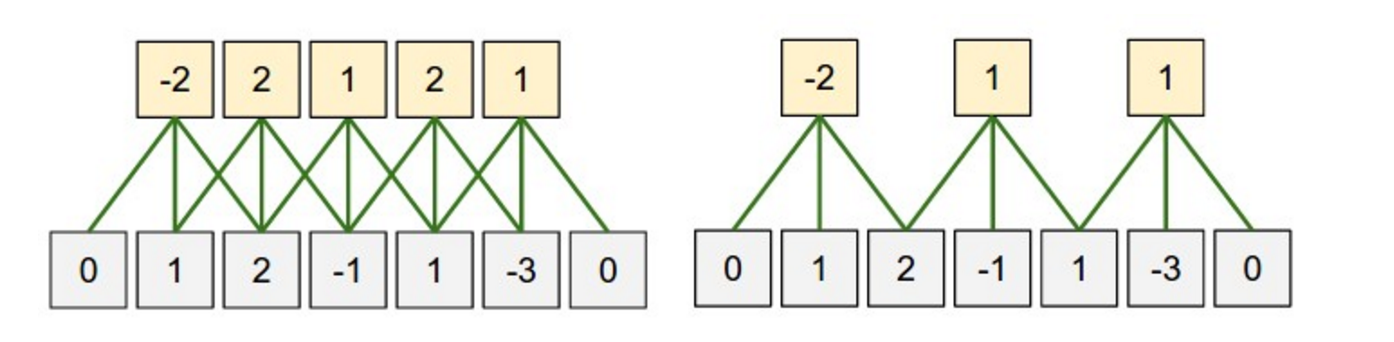
池化层
通常用池化层对输入进行子采样。一般是用最大池化。以下举出了一个 2*2 窗口的最大池化(在 NLP 中,通常对一个 filter 的整个输出进行池化,每个滤波器只产生一个数字)。
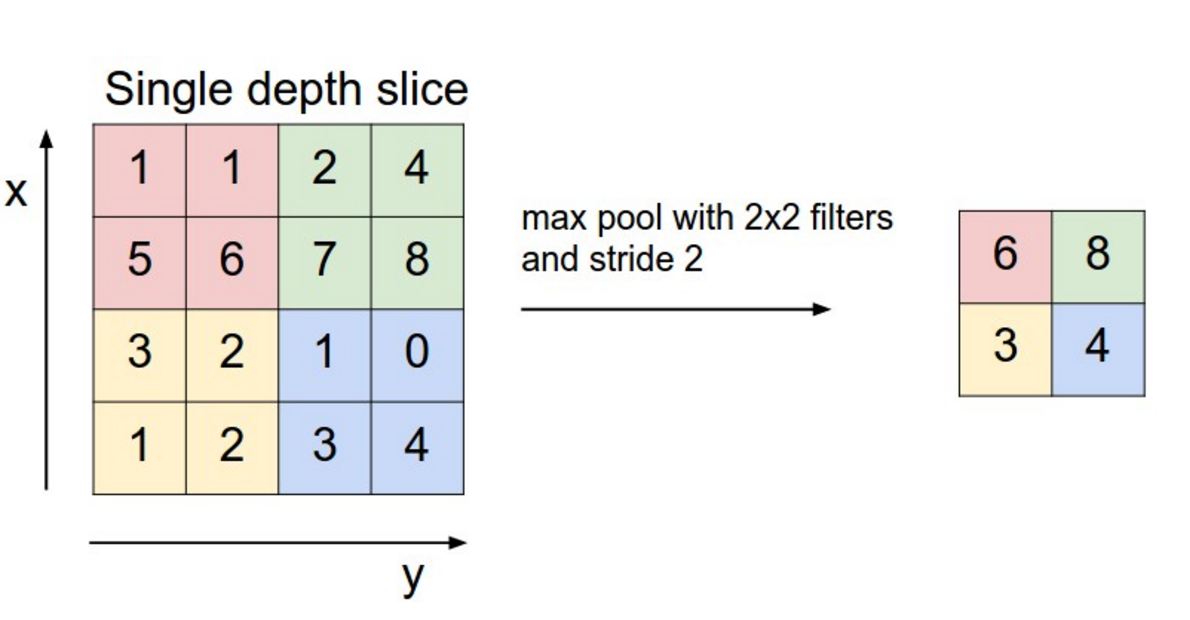
图 4:CNN 中的池化
为什么要池化?
-
可以提供一个固定输出大小的矩阵
- 也就是无论 filter 的大小或输入的大小如何,都能获得固定大小的输出。可以始终获得相同大小的输入进行分类。
-
获取最显著的信息
- 每个 filter 相当于检测某个特定功能。如果检测到本功能,就会输出一个比较大的数值,如果没有检测到,就会输出一个比较小的数值。通过执行最大池化可以获得本句是否有该特征信息。但是丢失了位置信息。
通道
在图像识别中,有 RGB 三个通道。在 NLP 中,可以有不同的 词嵌入(word embeddings) ,比如 word2vec 或者 GloVe。或者同一个句子用不同的语言表达。
CNN 在 NLP 中的应用
最适合 CNN 的应用是分类任务。比如情感分析,垃圾邮件检测或主题分类。卷积和合并操作会丢失有关本地字词顺序的信息,因此像词性标注(PoS Tagging)或者实体提取(Entity Extraction)不太适合 CNN。
[1]验证了一种 CNN 结构,主要使用的是情感分析和主题分类数据集。这一 CNN 结构在数据集上取得了非常好的性能,并且有一些 尖端技术(state-of-art)。
输 入 层 :由word2vec词嵌入拼接组成的句子
隐 藏 层 :带有多个filter的卷积层
Max\_pool:一个池化层
输 出 层 :送入softmax分类器
本文还利用两个通道分别是静态 词嵌入 和动态 词嵌入 进行实验,其中一个通道在训练期间会被调整,另一个不会。文献[2]提出了一个类似的但是更复杂的架构。[6]添加了一个额外的层,用来执行“语义聚类”。
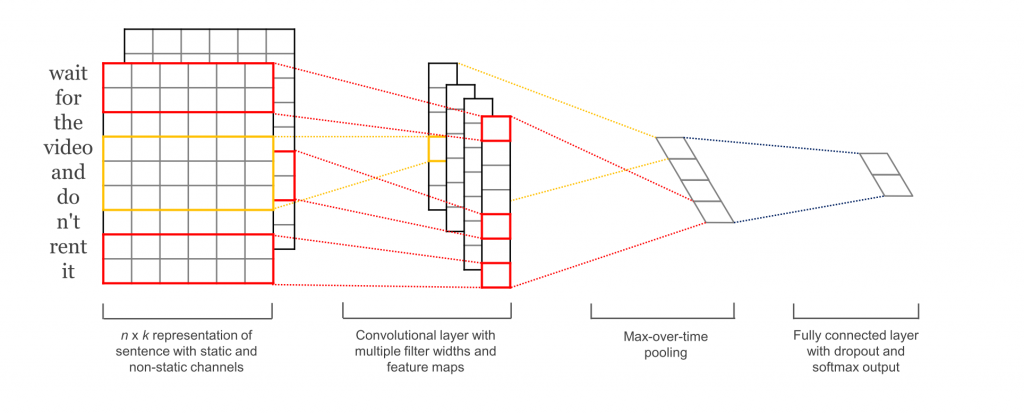
图 5:NLP 中的 CNN 模型
[4]从零开始训练向量,不需要 word2vec 或 GloVe 这样的预先训练的单词向量,而是直接把卷积应用在 one-hot 向量上。作者还为输入数据提出了一种节省空间的类词袋模型(bag-of-works-like),减少了神经网络需要学习的参数数量。[5]添加了一个额外的无监督的“区域嵌入”,通过 CNN 预测文本区域的上下文来学习。这个模型对长文本(比如影评)有效,在短文本(比如推文)上的表现还不清楚。
预先训练的词嵌入,对于短文本效果更好。
构建一个 CNN 框架需要选择很多超参数。其中包括:
- 输入表示(word2vec,GloVe,one-hot)
- filter 的数量和型号
- 池化策略(最大池化,平均池化)
- 激活函数(ReLU,tanh)
[7]对 CNN 结构中各种超参数的影响进行了评估。结果是:
- 最大池化总是优于平均池化
- 理想滤波器型号很重要,但是具体依赖于任务
- 在 NLP 任务中,正则化作用并不明显
以上这些结论使用的数据的长度差距不大,所以如果数据长度差距很大可能不适用。
并不是所有论文都把重点放在训练或研究嵌入学习的意义。大多数 CNN 框架都把词或句子嵌入(低维表示)作为训练过程的一部分。[13]提出了一种 CNN 框架用于预测 facebook 帖子的主题标签,同时为单词和句子生成了有意义的嵌入。然后,这一训练好的嵌入被成功用于其他任务——推荐感兴趣文档。
字符级别的 CNN
到目前为止,所有的模型都是根据单词的。但是,也有一些研究将 CNN 应用于字符。[14]研究了字符嵌入,与预训练的词嵌入一起用于 CNN 做词性标注。[15-16]尝试让 CNN 直接从字符学习,不需要预训练的嵌入。作者使用了 9 层网络,将其用于情感分析和文本分析。结果显示,在大型数据集上工作得很好,在小型数据集上表现不佳。
Reference
- [1] Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), 1746–1751.
- [2] Kalchbrenner, N., Grefenstette, E., & Blunsom, P. (2014). A Convolutional Neural Network for Modelling Sentences. Acl, 655–665.
- [3] Santos, C. N. dos, & Gatti, M. (2014). Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts. In COLING-2014 (pp. 69–78).
- [4] Johnson, R., & Zhang, T. (2015). Effective Use of Word Order for Text Categorization with Convolutional Neural Networks. To Appear: NAACL-2015, (2011).
- [5] Johnson, R., & Zhang, T. (2015). Semi-supervised Convolutional Neural Networks for Text Categorization via Region Embedding.
- [6] Wang, P., Xu, J., Xu, B., Liu, C., Zhang, H., Wang, F., & Hao, H. (2015). Semantic Clustering and Convolutional Neural Network for Short Text Categorization. Proceedings ACL 2015, 352–357.
- [7] Zhang, Y., & Wallace, B. (2015). A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification.
- [8] Nguyen, T. H., & Grishman, R. (2015). Relation Extraction: Perspective from Convolutional Neural Networks. Workshop on Vector Modeling for NLP, 39–48.
- [9] Sun, Y., Lin, L., Tang, D., Yang, N., Ji, Z., & Wang, X. (2015). Modeling Mention , Context and Entity with Neural Networks for Entity Disambiguation, (Ijcai), 1333–1339.
- [10] Zeng, D., Liu, K., Lai, S., Zhou, G., & Zhao, J. (2014). Relation Classification via Convolutional Deep Neural Network. Coling, (2011), 2335–2344.
- [11] Gao, J., Pantel, P., Gamon, M., He, X., & Deng, L. (2014). Modeling Interestingness with Deep Neural Networks.
- [12] Shen, Y., He, X., Gao, J., Deng, L., & Mesnil, G. (2014). A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval. Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management – CIKM ’14, 101–110.
- [13] Weston, J., & Adams, K. (2014). # T AG S PACE : Semantic Embeddings from Hashtags, 1822–1827.
- [14] Santos, C., & Zadrozny, B. (2014). Learning Character-level Representations for Part-of-Speech Tagging. Proceedings of the 31st International Conference on Machine Learning, ICML-14(2011), 1818–1826.
- [15] Zhang, X., Zhao, J., & LeCun, Y. (2015). Character-level Convolutional Networks for Text Classification, 1–9.
- [16] Zhang, X., & LeCun, Y. (2015). Text Understanding from Scratch. arXiv E-Prints, 3, 011102.
欢迎来到这里!
我们正在构建一个小众社区,大家在这里相互信任,以平等 • 自由 • 奔放的价值观进行分享交流。最终,希望大家能够找到与自己志同道合的伙伴,共同成长。
注册 关于