第三篇 爬取队列的实现
第二篇中,实现了深度爬取的过程,但其中一个比较明显的问题就是没有实现每个爬取作为一个独立的任务来执行;即串行的爬取网页中的链接;因此,这一篇将主要集中目标在并发的爬网页的问题上
目标是每个链接的爬取都当做一个独立的 job 来执行
设计
分工说明
- 每个 job 都是独立的爬取任务,且只爬取对应的网址
- 一个阻塞队列,用于保存所有需要爬取的网址
- 一个控制器,从队列中获取待爬取的链接,然后新建一个任务执行
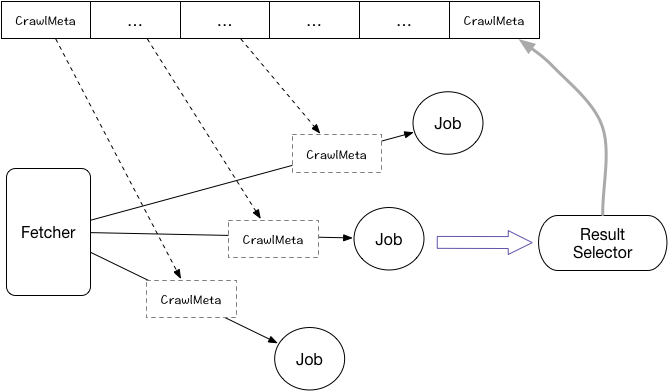
图解说明
-
Fetcher: 从队列中获取
CrawlMeta, 然后创建一个 Job 任务开始执行 -
Job: 根据
CrawlMeta爬取对应的网页,爬完之后将结果塞入ResultSelector -
ResultSelector : 分析爬取的结果,将所有满足条件的链接抽出来,封装对应的
CrawlMeta塞入队列
然后上面组成一个循环,即可实现自动的深度爬取
1. CrawlMeta
meta 对象,保存的是待爬取的 url 和对应的选择规则,链接过滤规则,现在则需要加一个当前深度的参数,表名当前爬取的 url 是第几层, 用于控制是否需要停止继续纵向的爬取
/**
* 当前爬取的深度
*/
@Getter
@Setter
private int currentDepth = 0;
2. FetchQueue
这个就是保存的待爬取网页的队列,其中包含两个数据结果
- toFetchQueue:
CrawlMeta队列,其中的都是需要爬取的 url- urls: 所有爬取过 or 待爬取的 url 集合,用于去重
源码如下,需要注意一下几个点
- tag: 之所以留了这个,主要是考虑我们的系统中是否可以存在多个爬取队列,如果存在时,则可以用 tag 来表示这个队列的用途
addSeed方法,内部先判断是否已经进入过队列了,若爬取了则不丢入待爬取队列(这个去重方式可以与上一篇实现的去重方式进行对比);获取队列中的第一个元素时,是没有加锁的,ArrayBlockingQueue内部保障了线程安全
/**
* 待爬的网页队列
* <p>
* Created by yihui on 2017/7/6.
*/
public class FetchQueue {
public static FetchQueue DEFAULT_INSTANCE = newInstance("default");
/**
* 表示爬取队列的标识
*/
private String tag;
/**
* 待爬取的网页队列
*/
private Queue<CrawlMeta> toFetchQueue = new ArrayBlockingQueue<>(200);
/**
* 所有爬取过的url集合, 用于去重
*/
private Set<String> urls = ConcurrentHashMap.newKeySet();
private FetchQueue(String tag) {
this.tag = tag;
}
public static FetchQueue newInstance(String tag) {
return new FetchQueue(tag);
}
/**
* 当没有爬取过时, 才丢入队列; 主要是避免重复爬取的问题
*
* @param crawlMeta
*/
public void addSeed(CrawlMeta crawlMeta) {
if (urls.contains(crawlMeta.getUrl())) {
return;
}
synchronized (this) {
if (urls.contains(crawlMeta.getUrl())) {
return;
}
urls.add(crawlMeta.getUrl());
toFetchQueue.add(crawlMeta);
}
}
public CrawlMeta pollSeed() {
return toFetchQueue.poll();
}
}
3. DefaultAbstractCrawlJob
默认的抽象爬取任务,第二篇深度爬取中是直接在这个 job 中执行了所有的深度爬取,这里我们需要抽里出来,改成每个 job 只爬取这个网页,至于网页内部的链接,则解析封装后丢入队列即可,不执行具体的抓去网页工作
需要先增加两个成员变量
/**
* 待爬取的任务队列
*/
private FetchQueue fetchQueue;
/**
* 解析的结果
*/
private CrawlResult crawlResult;
然后执行爬取的逻辑修改一下,主要的逻辑基本上没有变化,只是将之前的迭代调用,改成塞入队列,改动如下
/**
* 执行抓取网页
*/
void doFetchPage() throws Exception {
HttpResponse response = HttpUtils.request(this.crawlMeta, httpConf);
String res = EntityUtils.toString(response.getEntity(), httpConf.getCode());
if (response.getStatusLine().getStatusCode() != HttpStatus.SC_OK) { // 请求成功
this.crawlResult = new CrawlResult();
this.crawlResult.setStatus(response.getStatusLine().getStatusCode(), response.getStatusLine().getReasonPhrase());
this.crawlResult.setUrl(crawlMeta.getUrl());
this.visit(this.crawlResult);
return;
}
// 网页解析
this.crawlResult = doParse(res, this.crawlMeta);
// 回调用户的网页内容解析方法
this.visit(this.crawlResult);
// 解析返回的网页中的链接,将满足条件的扔到爬取队列中
int currentDepth = this.crawlMeta.getCurrentDepth();
if (currentDepth > depth) {
return;
}
Elements elements = crawlResult.getHtmlDoc().select("a[href]");
String src;
for (Element element : elements) {
// 确保将相对地址转为绝对地址
src = element.attr("abs:href");
if (!matchRegex(src)) {
continue;
}
CrawlMeta meta = new CrawlMeta(currentDepth + 1,
src,
this.crawlMeta.getSelectorRules(),
this.crawlMeta.getPositiveRegex(),
this.crawlMeta.getNegativeRegex());
fetchQueue.addSeed(meta);
}
}
String res = EntityUtils.toString(response.getEntity(), httpConf.getCode());
上面的代码,与之前有一行需要注意下, 这里对结果进行解析时,之前没有考虑字符编码的问题,因此全部走的都是默认编码逻辑,对应的源码如下,其中 defaultCharset = null, 因此最终的编码可能是 ISO_8859_1 也可能是解析的编码方式,所以在不指定编码格式时,可能出现乱码问题
Charset charset = null;
try {
ContentType contentType = ContentType.get(entity);
if(contentType != null) {
charset = contentType.getCharset();
}
} catch (UnsupportedCharsetException var13) {
throw new UnsupportedEncodingException(var13.getMessage());
}
if(charset == null) {
charset = defaultCharset;
}
if(charset == null) {
charset = HTTP.DEF_CONTENT_CHARSET;
}
为了解决乱码问题,在 HttpConf (与网络相关的配置项)中新添加了一个 code 参数,表示对应的编码,因为目前我们的教程还没有到网络相关的模块,所以先采用了最简单的实现方式,在 DefaultAbstractCrawlJob 中加了一个方法(后面的测试会给出对应的使用姿势)
protected void setResponseCode(String code) {
httpConf.setCode(code);
}
4. Fetcher
这个就是我们新增的爬取控制类,在这里实现从队列中获取任务,然后创建 job 来执行
因为职责比较清晰,所以一个最简单的实现如下
public class Fetcher {
private int maxDepth;
private FetchQueue fetchQueue;
public FetchQueue addFeed(CrawlMeta feed) {
fetchQueue.addSeed(feed);
return fetchQueue;
}
public Fetcher() {
this(0);
}
public Fetcher(int maxDepth) {
this.maxDepth = maxDepth;
fetchQueue = FetchQueue.DEFAULT_INSTANCE;
}
public <T extends DefaultAbstractCrawlJob> void start(Class<T> clz) throws Exception {
CrawlMeta crawlMeta;
int i = 0;
while (true) {
crawlMeta = fetchQueue.pollSeed();
if (crawlMeta == null) {
Thread.sleep(200);
if (++i > 300) { // 连续一分钟内没有数据时,退出
break;
}
continue;
}
i = 0;
DefaultAbstractCrawlJob job = clz.newInstance();
job.setDepth(this.maxDepth);
job.setCrawlMeta(crawlMeta);
job.setFetchQueue(fetchQueue);
new Thread(job, "crawl-thread-" + System.currentTimeMillis()).start();
}
}
}
5. 测试
测试代码与之前就有些区别了,比之前要简洁一些
public class QueueCrawlerTest {
public static class QueueCrawlerJob extends DefaultAbstractCrawlJob {
public void beforeRun() {
// 设置返回的网页编码
super.setResponseCode("gbk");
}
@Override
protected void visit(CrawlResult crawlResult) {
System.out.println(Thread.currentThread().getName() + " ___ " + crawlResult.getUrl());
}
}
public static void main(String[] rags) throws Exception {
Fetcher fetcher = new Fetcher(1);
String url = "http://chengyu.t086.com/gushi/1.htm";
CrawlMeta crawlMeta = new CrawlMeta();
crawlMeta.setUrl(url);
crawlMeta.addPositiveRegex("http://chengyu.t086.com/gushi/[0-9]+\\.htm$");
fetcher.addFeed(crawlMeta);
fetcher.start(QueueCrawlerJob.class);
}
}
输出结果如下
crawl-thread-1499333696153 ___ http://chengyu.t086.com/gushi/1.htm
crawl-thread-1499333710801 ___ http://chengyu.t086.com/gushi/3.htm
crawl-thread-1499333711142 ___ http://chengyu.t086.com/gushi/7.htm
crawl-thread-1499333710801 ___ http://chengyu.t086.com/gushi/2.htm
crawl-thread-1499333710802 ___ http://chengyu.t086.com/gushi/6.htm
crawl-thread-1499333710801 ___ http://chengyu.t086.com/gushi/4.htm
crawl-thread-1499333710802 ___ http://chengyu.t086.com/gushi/5.htm
改进
和之前一样,接下来就是对上面的实现进行缺点分析和改进
1. 待改善点
- Fetcher 中,每个任务都起一个线程,可以用线程池来优化管理
- Job 中执行任务和结果分析没有拆分,离我们的 job 只做爬取的逻辑有一点差距
- 退出程序的逻辑比较猥琐
- 爬取网页的间隔时间可以加一下
- 频繁的 Job 对象创建与销毁,是否可以考虑对象池的方式减少 gc
2. 线程池
直接使用 Java 的线程池来操作,因为线程池有较多的配置参数,所以先定义一个配置类; 给了一个默认的配置项,这个可能并不满足实际的业务场景,参数配置需要和实际的爬取任务相关联,才可以达到最佳的使用体验
// Fetcher.java
@Getter
@Setter
@ToString
@NoArgsConstructor
public static class ThreadConf {
private int coreNum = 6;
private int maxNum = 10;
private int queueSize = 10;
private int aliveTime = 1;
private TimeUnit timeUnit = TimeUnit.MINUTES;
private String threadName = "crawl-fetch";
public final static ThreadConf DEFAULT_CONF = new ThreadConf();
}
线程池初始化
private Executor executor;
@Setter
private ThreadConf threadConf;
/**
* 初始化线程池
*/
private void initExecutor() {
executor = new ThreadPoolExecutor(threadConf.getCoreNum(),
threadConf.getMaxNum(),
threadConf.getAliveTime(),
threadConf.getTimeUnit(),
new LinkedBlockingQueue<>(threadConf.getQueueSize()),
new CustomThreadFactory(threadConf.getThreadName()),
new ThreadPoolExecutor.CallerRunsPolicy());
}
任务执行,直接将原来的创建 Thread 方式改成线程池执行方式即可
// com.quick.hui.crawler.core.fetcher.Fetcher#start
executor.execute(job);
测试 case 与之前一样,输出有些区别(主要是线程的名不同), 可以看到其中 crawl-fetch-1 有两个,因为我们设置的线程的 coreSize = 6 , 而实际的爬取任务有 7 个,说明有一个被重用了;当爬取任务较多时,这么做的好处就很明显了
crawl-fetch-1 ___ http://chengyu.t086.com/gushi/1.htm
crawl-fetch-2 ___ http://chengyu.t086.com/gushi/2.htm
crawl-fetch-5 ___ http://chengyu.t086.com/gushi/5.htm
crawl-fetch-1 ___ http://chengyu.t086.com/gushi/7.htm
crawl-fetch-3 ___ http://chengyu.t086.com/gushi/3.htm
crawl-fetch-4 ___ http://chengyu.t086.com/gushi/4.htm
crawl-fetch-6 ___ http://chengyu.t086.com/gushi/6.htm
3. ResultFilter
用于结果解析的类,扫描爬取网页中的链接,将满足条件的链接封装之后塞入待爬取队列
这个实现比较简单,比较难处理的是如何判断是否抓取完的逻辑
一个简单的思路如下:
- 从第 0 层(seed)出发, 可以知道第一层有 count 个任务
- 从第一层的第 0 个出发,有 count10 个任务; 第 1 个出发,有 count11 个任务
- 从第二层的第 0 个出发,有 count20 个任务...
当扫描到最后一层时,上一层的完成计数 +1,如果此时上一次的完成计数正好等于任务数,则上上一层计数 +1,依次知道第 0 层的计数等于 count,此时才表示爬取完成
计数配置 JobCount
每个爬取的 job,都对应一个 JobCount , 注意其中的几个属性,以及要求保证 JobCount 的 id 全局唯一
@Getter
public class JobCount {
public static int SEED_ID = 1;
public static AtomicInteger idGen = new AtomicInteger(0);
public static int genId() {
return idGen.addAndGet(1);
}
/**
* 该Job对应的唯一ID
*/
private int id;
/**
* 该job对应父job的id
*/
private int upperId;
/**
* 当前的层数
*/
private int currentDepth;
/**
* 该job对应的网页中,子Job的数量
*/
private AtomicInteger jobCount = new AtomicInteger(0);
/**
* 该Job对应的网页中, 子Job完成的数量
*/
private AtomicInteger finishCount = new AtomicInteger(0);
public boolean fetchOver() {
return jobCount.get() == finishCount.get();
}
/**
* 爬取完成一个子任务
*/
public synchronized boolean finishJob() {
finishCount.addAndGet(1);
return fetchOver();
}
public JobCount(int id, int upperId, int currentDepth, int jobCount, int finishCount) {
this.id = id;
this.upperId = upperId;
this.currentDepth = currentDepth;
this.jobCount.set(jobCount);
this.finishCount.set(finishCount);
}
}
将 Job 任务与 JobCount 关联,因此在 CrwalMeta 中新增两个属性
/**
* 当前任务对应的 {@link JobCount#id }
*/
@Getter
@Setter
private int jobId;
/**
* 当前任务对应的 {@link JobCount#parentId }
*/
@Getter
@Setter
private int parentJobId;
爬取队列中做出相应的调整,新增一个 isOver 属性,用于确定是否结束;一个 jobCountMap 用于记录每个 Job 的计数情况
对应的 FetchQueue 修改代码如下, 需要注意的是几个 finishOneJob 方法的实现方式
/**
* JobCount 映射表, key为 {@link JobCount#id}, value 为对应的JobCount
*/
public Map<Integer, JobCount> jobCountMap = new ConcurrentHashMap<>();
/**
* 爬取是否完成的标识
*/
public volatile boolean isOver = false;
/**
* 当没有爬取过时, 才丢入队列; 主要是避免重复爬取的问题
*
* @param crawlMeta
*/
public boolean addSeed(CrawlMeta crawlMeta) {
if (urls.contains(crawlMeta.getUrl())) {
return false;
}
synchronized (this) {
if (urls.contains(crawlMeta.getUrl())) {
return false;
}
urls.add(crawlMeta.getUrl());
toFetchQueue.add(crawlMeta);
return true;
}
}
public CrawlMeta pollSeed() {
return toFetchQueue.poll();
}
public void finishJob(CrawlMeta crawlMeta, int count, int maxDepth) {
if (finishOneJob(crawlMeta, count, maxDepth)) {
isOver = true;
System.out.println("============ finish crawl! ======");
}
}
/**
* 完成一个爬取任务
*
* @param crawlMeta 爬取的任务
* @param count 爬取的网页上满足继续爬取的链接数
* @return 如果所有的都爬取完了, 则返回true
*/
private boolean finishOneJob(CrawlMeta crawlMeta, int count, int maxDepth) {
JobCount jobCount = new JobCount(crawlMeta.getJobId(),
crawlMeta.getParentJobId(),
crawlMeta.getCurrentDepth(),
count, 0);
jobCountMap.put(crawlMeta.getJobId(), jobCount);
if (crawlMeta.getCurrentDepth() == 0) { // 爬取种子页时,特判一下
return count == 0; // 若没有子链接可以爬取, 则直接结束
}
if (count == 0 || crawlMeta.getCurrentDepth() == maxDepth) {
// 当前的为最后一层的job时, 上一层计数+1
return finishOneJob(jobCountMap.get(crawlMeta.getParentJobId()));
}
return false;
}
/**
* 递归向上进行任务完成 +1
*
* @param jobCount
* @return true 表示所有的任务都爬取完成
*/
private boolean finishOneJob(JobCount jobCount) {
if (jobCount.finishJob()) {
if (jobCount.getCurrentDepth() == 0) {
return true; // 结束
}
return finishOneJob(jobCountMap.get(jobCount.getParentId()));
}
return false;
}
所以 Fetch 类中的循环判断条件调整为根据 fetchQueue 的 isOver 来作为判定条件
public <T extends DefaultAbstractCrawlJob> void start(Class<T> clz) throws Exception {
CrawlMeta crawlMeta;
while (!fetchQueue.isOver) {
crawlMeta = fetchQueue.pollSeed();
if (crawlMeta == null) {
Thread.sleep(200);
continue;
}
DefaultAbstractCrawlJob job = clz.newInstance();
job.setDepth(this.maxDepth);
job.setCrawlMeta(crawlMeta);
job.setFetchQueue(fetchQueue);
executor.execute(job);
}
}
至此上面实现了结束判定条件的设置,下面则是读 Job 中的代码进行分拆,将爬取的网页中链接过滤逻辑,迁移到 ResultFilter 中实现,基本上就是代码的迁移
public class ResultFilter {
public static void filter(CrawlMeta crawlMeta,
CrawlResult crawlResult,
FetchQueue fetchQueue,
int maxDepth) {
int count = 0;
try {
// 解析返回的网页中的链接,将满足条件的扔到爬取队列中
int currentDepth = crawlMeta.getCurrentDepth();
if (currentDepth >= maxDepth) {
return;
}
// 当前的网址中可以继续爬的链接数
Elements elements = crawlResult.getHtmlDoc().select("a[href]");
String src;
for (Element element : elements) {
// 确保将相对地址转为绝对地址
src = element.attr("abs:href");
if (!matchRegex(crawlMeta, src)) {
continue;
}
CrawlMeta meta = new CrawlMeta(
JobCount.genId(),
crawlMeta.getJobId(),
currentDepth + 1,
src,
crawlMeta.getSelectorRules(),
crawlMeta.getPositiveRegex(),
crawlMeta.getNegativeRegex());
if (fetchQueue.addSeed(meta)) {
count++;
}
}
} finally { // 上一层爬完计数+1
fetchQueue.finishJob(crawlMeta, count, maxDepth);
}
}
private static boolean matchRegex(CrawlMeta crawlMeta, String url) {
Matcher matcher;
for (Pattern pattern : crawlMeta.getPositiveRegex()) {
matcher = pattern.matcher(url);
if (matcher.find()) {
return true;
}
}
for (Pattern pattern : crawlMeta.getNegativeRegex()) {
matcher = pattern.matcher(url);
if (matcher.find()) {
return false;
}
}
return crawlMeta.getPositiveRegex().size() == 0;
}
}
测试代码与之前加一点变化,将深度设置为 2,抓去的正则有小的调整
public class QueueCrawlerTest {
public static class QueueCrawlerJob extends DefaultAbstractCrawlJob {
public void beforeRun() {
// 设置返回的网页编码
super.setResponseCode("gbk");
}
@Override
protected void visit(CrawlResult crawlResult) {
System.out.println(Thread.currentThread().getName() + "___" + crawlMeta.getCurrentDepth() + "___" + crawlResult.getUrl());
}
}
@Test
public void testCrawel() throws Exception {
Fetcher fetcher = new Fetcher(2);
String url = "http://chengyu.t086.com/gushi/1.htm";
CrawlMeta crawlMeta = new CrawlMeta();
crawlMeta.setUrl(url);
crawlMeta.addPositiveRegex("http://chengyu.t086.com/gushi/[0-9]+\\.html$");
fetcher.addFeed(crawlMeta);
fetcher.start(QueueCrawlerJob.class);
}
}
输出结果如下
crawl-fetch-1___0___http://chengyu.t086.com/gushi/1.htm
crawl-fetch-7___1___http://chengyu.t086.com/gushi/673.html
crawl-fetch-1___1___http://chengyu.t086.com/gushi/683.html
crawl-fetch-3___1___http://chengyu.t086.com/gushi/687.html
crawl-fetch-8___1___http://chengyu.t086.com/gushi/672.html
crawl-fetch-4___1___http://chengyu.t086.com/gushi/686.html
crawl-fetch-2___1___http://chengyu.t086.com/gushi/688.html
crawl-fetch-6___1___http://chengyu.t086.com/gushi/684.html
crawl-fetch-10___1___http://chengyu.t086.com/gushi/670.html
main___1___http://chengyu.t086.com/gushi/669.html
crawl-fetch-5___1___http://chengyu.t086.com/gushi/685.html
crawl-fetch-9___1___http://chengyu.t086.com/gushi/671.html
crawl-fetch-6___1___http://chengyu.t086.com/gushi/679.html
crawl-fetch-10___1___http://chengyu.t086.com/gushi/677.html
crawl-fetch-8___1___http://chengyu.t086.com/gushi/682.html
crawl-fetch-7___1___http://chengyu.t086.com/gushi/681.html
crawl-fetch-2___1___http://chengyu.t086.com/gushi/676.html
main___1___http://chengyu.t086.com/gushi/660.html
crawl-fetch-4___1___http://chengyu.t086.com/gushi/680.html
crawl-fetch-5___1___http://chengyu.t086.com/gushi/675.html
crawl-fetch-1___1___http://chengyu.t086.com/gushi/678.html
crawl-fetch-9___1___http://chengyu.t086.com/gushi/674.html
crawl-fetch-3___1___http://chengyu.t086.com/gushi/668.html
crawl-fetch-6___1___http://chengyu.t086.com/gushi/667.html
crawl-fetch-10___1___http://chengyu.t086.com/gushi/666.html
crawl-fetch-8___1___http://chengyu.t086.com/gushi/665.html
crawl-fetch-4___1___http://chengyu.t086.com/gushi/662.html
crawl-fetch-5___1___http://chengyu.t086.com/gushi/661.html
main___1___http://chengyu.t086.com/gushi/651.html
crawl-fetch-3___1___http://chengyu.t086.com/gushi/657.html
crawl-fetch-9___1___http://chengyu.t086.com/gushi/658.html
crawl-fetch-2___1___http://chengyu.t086.com/gushi/663.html
crawl-fetch-7___1___http://chengyu.t086.com/gushi/664.html
crawl-fetch-1___1___http://chengyu.t086.com/gushi/659.html
crawl-fetch-6___1___http://chengyu.t086.com/gushi/656.html
crawl-fetch-10___1___http://chengyu.t086.com/gushi/655.html
crawl-fetch-4___1___http://chengyu.t086.com/gushi/653.html
crawl-fetch-5___1___http://chengyu.t086.com/gushi/652.html
crawl-fetch-8___1___http://chengyu.t086.com/gushi/654.html
crawl-fetch-3___1___http://chengyu.t086.com/gushi/650.html
crawl-fetch-2___1___http://chengyu.t086.com/gushi/648.html
crawl-fetch-9___1___http://chengyu.t086.com/gushi/649.html
crawl-fetch-7___1___http://chengyu.t086.com/gushi/647.html
main___1___http://chengyu.t086.com/gushi/640.html
crawl-fetch-10___1___http://chengyu.t086.com/gushi/644.html
crawl-fetch-6___1___http://chengyu.t086.com/gushi/645.html
crawl-fetch-4___1___http://chengyu.t086.com/gushi/643.html
crawl-fetch-1___1___http://chengyu.t086.com/gushi/646.html
crawl-fetch-8___1___http://chengyu.t086.com/gushi/641.html
crawl-fetch-5___1___http://chengyu.t086.com/gushi/642.html
crawl-fetch-3___1___http://chengyu.t086.com/gushi/639.html
crawl-fetch-9___1___http://chengyu.t086.com/gushi/635.html
crawl-fetch-6___1___http://chengyu.t086.com/gushi/637.html
crawl-fetch-7___1___http://chengyu.t086.com/gushi/634.html
main___1___http://chengyu.t086.com/gushi/629.html
crawl-fetch-10___1___http://chengyu.t086.com/gushi/638.html
crawl-fetch-4___1___http://chengyu.t086.com/gushi/633.html
crawl-fetch-1___1___http://chengyu.t086.com/gushi/632.html
crawl-fetch-2___1___http://chengyu.t086.com/gushi/636.html
crawl-fetch-5___1___http://chengyu.t086.com/gushi/630.html
crawl-fetch-8___1___http://chengyu.t086.com/gushi/631.html
crawl-fetch-9___1___http://chengyu.t086.com/gushi/627.html
crawl-fetch-3___1___http://chengyu.t086.com/gushi/628.html
main___1___http://chengyu.t086.com/gushi/617.html
crawl-fetch-7___1___http://chengyu.t086.com/gushi/625.html
crawl-fetch-1___1___http://chengyu.t086.com/gushi/622.html
crawl-fetch-10___1___http://chengyu.t086.com/gushi/624.html
crawl-fetch-6___1___http://chengyu.t086.com/gushi/626.html
crawl-fetch-4___1___http://chengyu.t086.com/gushi/623.html
crawl-fetch-2___1___http://chengyu.t086.com/gushi/621.html
crawl-fetch-5___1___http://chengyu.t086.com/gushi/620.html
crawl-fetch-1___1___http://chengyu.t086.com/gushi/614.html
crawl-fetch-9___1___http://chengyu.t086.com/gushi/618.html
crawl-fetch-6___1___http://chengyu.t086.com/gushi/612.html
crawl-fetch-4___1___http://chengyu.t086.com/gushi/611.html
crawl-fetch-8___1___http://chengyu.t086.com/gushi/619.html
crawl-fetch-3___1___http://chengyu.t086.com/gushi/616.html
crawl-fetch-7___1___http://chengyu.t086.com/gushi/615.html
main___1___http://chengyu.t086.com/gushi/605.html
crawl-fetch-10___1___http://chengyu.t086.com/gushi/613.html
crawl-fetch-2___1___http://chengyu.t086.com/gushi/610.html
crawl-fetch-5___1___http://chengyu.t086.com/gushi/609.html
crawl-fetch-1___1___http://chengyu.t086.com/gushi/608.html
crawl-fetch-6___1___http://chengyu.t086.com/gushi/606.html
crawl-fetch-9___1___http://chengyu.t086.com/gushi/607.html
crawl-fetch-8___1___http://chengyu.t086.com/gushi/603.html
main___1___http://chengyu.t086.com/gushi/594.html
crawl-fetch-4___1___http://chengyu.t086.com/gushi/604.html
crawl-fetch-7___1___http://chengyu.t086.com/gushi/600.html
crawl-fetch-10___1___http://chengyu.t086.com/gushi/602.html
crawl-fetch-2___1___http://chengyu.t086.com/gushi/599.html
crawl-fetch-3___1___http://chengyu.t086.com/gushi/601.html
crawl-fetch-5___1___http://chengyu.t086.com/gushi/598.html
crawl-fetch-6___1___http://chengyu.t086.com/gushi/596.html
crawl-fetch-1___1___http://chengyu.t086.com/gushi/597.html
crawl-fetch-4___1___http://chengyu.t086.com/gushi/593.html
crawl-fetch-8___1___http://chengyu.t086.com/gushi/591.html
crawl-fetch-9___1___http://chengyu.t086.com/gushi/595.html
crawl-fetch-7___1___http://chengyu.t086.com/gushi/592.html
main___2___http://chengyu.t086.com/gushi/583.html
crawl-fetch-3___2___http://chengyu.t086.com/gushi/588.html
crawl-fetch-10___1___http://chengyu.t086.com/gushi/590.html
crawl-fetch-2___1___http://chengyu.t086.com/gushi/589.html
crawl-fetch-5___2___http://chengyu.t086.com/gushi/579.html
crawl-fetch-1___2___http://chengyu.t086.com/gushi/581.html
crawl-fetch-7___2___http://chengyu.t086.com/gushi/584.html
crawl-fetch-4___2___http://chengyu.t086.com/gushi/582.html
crawl-fetch-3___2___http://chengyu.t086.com/gushi/587.html
crawl-fetch-6___2___http://chengyu.t086.com/gushi/580.html
crawl-fetch-9___2___http://chengyu.t086.com/gushi/585.html
crawl-fetch-8___2___http://chengyu.t086.com/gushi/586.html
crawl-fetch-10___2___http://chengyu.t086.com/gushi/578.html
crawl-fetch-1___2___http://chengyu.t086.com/gushi/575.html
crawl-fetch-2___2___http://chengyu.t086.com/gushi/577.html
crawl-fetch-5___2___http://chengyu.t086.com/gushi/576.html
crawl-fetch-7___2___http://chengyu.t086.com/gushi/574.html
============ finish crawl! ======
小结
本片主要集中在一个爬取队列 + 线程池方式,来实现并发的爬取任务,同时实现了一个比较猥琐的结束爬取的方案
缺陷
上面的实现,有一个非常明显的缺陷,就是相应的日志输出太少,下一篇博文将着手于此,将一些关键链路的日志信息打印出来;同时将剩下的几个待优化点一并做掉
到这里,基本上一个爬虫框架的雏形算是基本完成(当然还有很多问题,如队列的深度,JobCountMap 可能爆掉,还有一些爬虫的基本注意事项等都有缺陷,但没关系,留待后续一点一点来完善)
源码地址
项目地址: https://github.com/liuyueyi/quick-crawler
优化前对应的 tag: v0.004
优化后对应的 tag: v0.005
欢迎来到这里!
我们正在构建一个小众社区,大家在这里相互信任,以平等 • 自由 • 奔放的价值观进行分享交流。最终,希望大家能够找到与自己志同道合的伙伴,共同成长。
注册 关于